

Как только вы создадите сайт для своего бизнеса, однозначно столкнетесь с понятием «индексация в поисковых системах». В этой статье специалисты Kokoc дали максимально возможные ответы на возможные вопросы, касающиеся индексации сайта. Также здесь вы найдете подробные практические рекомендации, как настроить индексацию сайта с учетом требования современного SEO. Статья будет полезна не только SEO-специалистам, но и маркетологам и предпринимателям.
- Что такое индексация в поисковых системах
- Как проходит процесс индексации
- Ключевые аспекты и принципы индексации в Google и «Яндекса»
- Как настроить индексацию сайта
- Как ускорить индексацию сайта
- Как запретить индексирование
- Распространенные ошибки индексирования
- Как проверить индексацию сайта
- FAQ по индексации сайтов
- Коротко о главном
Что такое индексация в поисковых системах
Под индексацией понимают добавление информации о сайте или странице в базу данных поисковой системы. Фактически поисковую базу можно сравнить с библиотечным каталогом, куда внесены данные о книгах. Только вместо книг здесь веб-страницы. Но в отличие от бумажного каталога, здесь постоянно происходит активный анализ контента. Поисковые системы хорошо понимают содержимое контента, поэтому они не просто хранят ссылки на сайты, а постоянно анализируют их содержимое.
Без качественной индексации ваш сайт не будет виден никому, поэтому настройка индексирования — фактически фундамент работы над сайтом и всех действий по привлечению органического трафика. И только потом уже добавляются все остальные элементы по оптимизации сайта. Если у веб-страницы будут проблемы с индексированием, ваш бизнес не получит клиентов с сайта и понесет убытки. Важно отметить, что с развитием поисковых технологий, индексация стала более сложным процессом. Поисковые системы не только собирают информацию о страницах, но и анализируют их содержимое, структуру и связи с другими ресурсами. Это позволяет более точно определять релевантность страниц для различных поисковых запросов.
Простыми словами, индексация — процесс сбора данных о сайте. Пока информация о новой странице не окажется в базе, ее не будут показывать по запросам пользователей. Это означает, что ваш сайт никто не увидит.
Как проходит процесс индексации
- Поисковый робот (краулер) обходит ресурсы и находит новую страницу. Дальше он начинает ее изучать.
- Данные анализируются: происходит очистка контента от ненужной информации, заодно формируется список лексем. Лексема — совокупность всех значений и грамматических форм слова в русском языке. Также в процессе анализа происходит оценка качества контента. Анализируется релевантность определенным ключевым запросам пользователей. Проверяется структура текстов на странице, чем лучше структурирован контент, тем для поисковой системы лучше. Выявляются сущности.
- Вся собранная информация упорядочивается, лексемы расставляются по алфавиту. Заодно происходит обработка данных, поисковая машина относит информацию к определенным тематикам.
- Формируется индексная запись. В ней содержатся основные данные собранные со страницы.
Это стандартный процесс индексации документов для поисковых систем. При этом у «Яндекса» и Google существуют небольшие отличия в технических моментах, про это мы расскажем дальше. Обратите внимание, что сейчас в процессе получения контента поисковыми системами используются в том числе и рендеринг JavaScript.
А в чем помогает JS при индексации? Он помогает правильно понять вёрстку, расположение элементов, какие-то дополнительные блоки, которые работают только исключительно с JS. И тем самым позволяя давать поисковому роботу больше представления о странице.


Ключевые аспекты и принципы индексации в Google и «Яндекса»
У разных поисковых систем принципы индексирования контента различаются. Это нужно учитывать при работе над сайтом. Ниже разберем основные особенности работы поисковых роботов.
Краулинговый бюджет
Под краулинговым бюджетом подразумевают ограничение на число сканируемых страниц сайта за определенный промежуток времени. Простыми словами, это лимит страниц, которые поисковый робот просканирует за одно посещение. Краулинговый бюджет определяется в зависимости от технического лимита сканирования допускаемого настройками сервера и объема запросов на сканирование со стороны сайта. Технически чем больше сайт и чаще он обновляется, тем больше у него будет краулинговый бюджет.
У «Яндекса» есть схожий инструмент, ну тут он определяется как динамический лимит на сканирование. Он зависит, в первую очередь, от размера сайта. В зависимости от частоты обновлений и наличия/отсутствия фильтров, динамический лимит может увеличиваться или уменьшаться.
Исторически «Яндекс» индексировал сайты медленнее, но сейчас отставание от Google в скорости индексации снижается. При этом если Google без проблем индексирует JS-сайты, «Яндекс» может их не сканировать если отключена серверный рендеринг JS.
Вот два основных фактора влияющих на краулинговый бюджет, которые нужно учитывать, если вы хотите правильно настроить индексацию:
- Скорость загрузки. Чем быстрее загружается ресурс, тем эффективнее происходит сканирование и поисковые роботы получают дополнительный сигнал, что на этот сайт стоит заходить чаще. Наоборот, при замедлении загрузки, индексация может замедляться, так поисковые системы борются со снижением качества пользовательского опыта.
- Структура сайта. Речь о структурировании внутренних ссылок. Если на вашем сайте структура хорошо настроена, все ссылки есть в файле Sitemap.xml, при переходе по самому сайту не возникает сложностей с попаданием на любые страницы, поисковые роботы будут эффективнее использовать краулинговый бюджет. Приведу пример. Если на сайте до любой страницы можно добраться в 2–3 клика, новые страницы будут индексироваться быстрее. Если же на сайте между главной страницей и новым документом находится 5–6 кликов, поисковый робот может не сразу добираться до него. А значит, документ будет попадать в индекс с задержкой.

Mobile-first indexing (Google)
С 2018 года в Google приоритет при ранжировании отдается мобильным версиям сайтов (Mobile-first). Фактически они отключили разделение индекса на мобильный и десктопный. Причем возможностей для переключения вариантов ранжирования и выбора определенного типа страниц для индексирования нет.
Технически Google ранжирует все сайты с качественным контентом, но приоритет отдается именно мобильным версиям. Поэтому необходимо следить за качеством мобильной версии сайта. Сейчас стандарт — адаптивная верстка. Для качественной и быстрой индексации обязательно отслеживайте правильность верстки для мобильных устройств.
У «Яндекса» аналогичные функции выполняет алгоритм «Владивосток». Отечественная поисковая система не отдает приоритета мобильным версиям при ранжировании, но учитывает их качество. В целом мобильные сайты должны хорошо смотреться на устройствах с маленьким экраном, а также соответствовать требованиям «Яндекса». Эти требования можно посмотреть в справке.
Core Web Vitals
Под этим термином подразумевается скорость загрузки и отрисовки элементов, интерактивность сайта. Этот набор параметров в первую очередь проверяется Google, у «Яндекса» это официально не заявлено. Вот основные особенности Core Web Vitals для разных поисковых систем:
- Google. Один из важных параметров при оценке мобильных сайтов. Влияет на скорость и эффективность индексирования сайта.
- «Яндекс». Официально не работает. Но, на практике алгоритмы учитывают не только скорость загрузки, но и удобство сайта. А вот интерактивность, вероятнее всего, не оценивается.

JavaScript SEO
Речь идет не только о сайтах, полностью сделанных на JS — например, с помощью фреймворков — но и о ресурсах, которые просто используют эту технологию в части кода. У разных поисковых систем процесс индексации отличается.
Google обходит все сайты, вне зависимости от используемых ими технологий, поэтому проблем с индексацией возникать не должно. Для рендеринга поисковый робот использует последнюю версию браузера Chromium. Вебмастеру необходимо регулярно проверять совместимость JS-кода с последними версиями этого браузерного движка.
«Яндекс» обходит только те страницы, которые не закрыты от сканирования в robots.txt. Но сейчас можно дополнительно настроить индексация JS-сайтов. Для этого в «Яндекс Вебмастере» есть специальный инструмент, позволяющий регулировать обход сайта поисковыми роботами.
Здесь и далее скриншоты сделаны автором статьи в его аккаунтах.
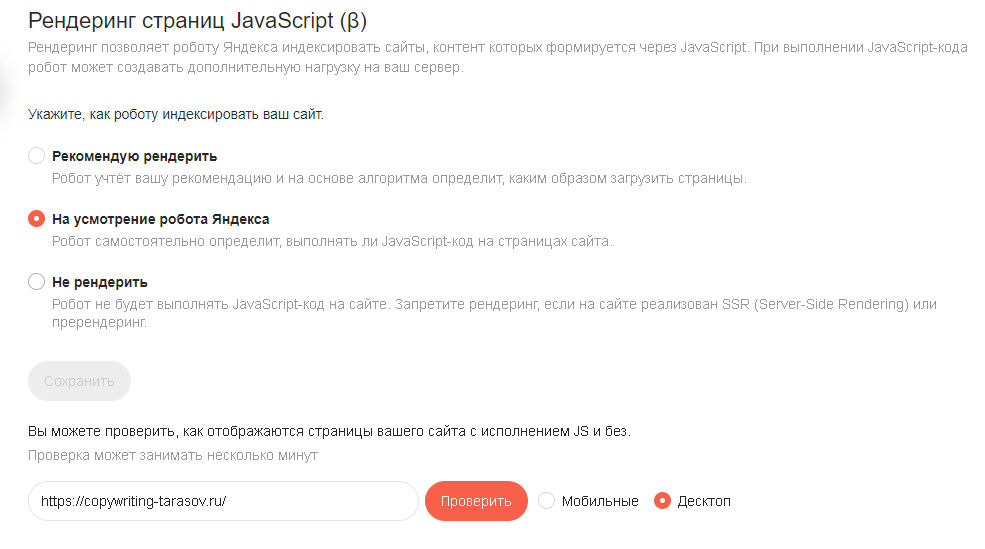
По умолчанию поисковый робот сам выбирает использовать ли JS при индексации. Вы можете полностью запретить рендеринг или рекомендовать роботу это делать.
Принципы анализа контента
Поисковые системы используют разные сигналы для оценки качества страниц и содержащегося на них контента. В случае с Google используются следующие принципы анализа контента сайтов:
- Работа на уровне странице. Каждый документ оценивается отдельно.
- Классификаторы. Контент страницы должен быть правильно размечен. Это упрощает и ускоряет индексацию сайта.
- Сочетания слов и контекст. Алгоритмы с применением искусственного интеллекта анализируют контент и проверяют насколько он релевантен запросам, соответствует ли страница интенту пользователя.
У «Яндекс» процесс индексирования немного отличается. Да, поисковые роботы работают тоже на уровне страниц, но они изначально ориентируются на мета-теги. Только потом уже изучают основной контент страницы.
Если на одном сайте в процессе анализа находится несколько страниц с одинаковым контентом, поисковый паук может посчитать их дублирующими и проиндексировать только одну из них. Учитывайте, что робот «Яндекса» первичную оценку делает исходя из общей структуры страницы, поэтому уделяйте внимание правильной структуре контента.

E-E-A-T
Определение E-E-A-T больше связано с Google. Именно в этой поисковой системе официально заявлены алгоритмы, работающие с этими факторами. Фактически Google оценивает контент не только по ключевым словам, но и авторитетности. Причем речь в первую очередь о тех сайтах, которые отвечают за благополучие человека: финансы, здоровье. Алгоритмы учитывают, кто стал автором статьи, насколько источникам использованным для контента можно доверять. Все это напрямую влияет на скорость индексации сайта.
В «Яндекс» официально не заявлялось об отдельных алгоритмах оценивающих E-E-A-T. Но при этом отмечается, что поисковые роботы оценивают авторитетность сайта. Учитывают наличие ссылок на официальные источники: СМИ, сборники законов. Все это показывает поисковой системе, что сайту можно доверять, а значит контент можно индексировать.
Доверие, авторитетность — вот эти сигналы, которые аббревиатурой E-E-A-T обозначаются. «Яндекс» в этом соответствует и учитывает.
Выскажу субъективное мнение, так как замеров нет, но по всем докладам «Яндекса», по практике анализа выдачи, все-таки «Яндекс» смотрит на репутационное окружение бизнеса, причем в основном на своих сервисах.
Для Google тоже можно так сказать, поисковая система учитывает как представлен бизнес на ее площадках. Но, в Google все же уклон больше в траст доверия с точки зрения своей базы знаний об авторах, наличие трастовых ссылок.
Как E-E-A-T влияет на индексацию и продвижение коммерческих сайтов?
Отдельно стоит рассмотреть, как E-E-A-T влияет на продвижение коммерческих сайтов. Для Google эти факторы влияют в первую очередь на медицинскую и финансовую тематику. Поисковый алгоритм учитывает авторитетность автора контента и другие сопутствующие факторы. Если сайт или страницы не соответствуют требованиям, ресурс будет хуже индексироваться.
В «Яндекс» подход несколько другой. Поисковые алгоритмы требуют соответствия E-E-A-T от всех коммерческих сайтов. Но, и сам набор факторов отличается. Автор контента может не учитываться, но вот наличие сертификатов, правоустанавливающих документов, юридического адреса и телефонов показывают поисковому роботу, что сайту можно доверять и проиндексировать его.
Как настроить индексацию сайта
Обычно поисковые системы самостоятельно находят и индексируют сайты, даже без специальных действий с вашей стороны. Однако современные веб-технологии, особенно использование JavaScript для динамической загрузки контента, могут создавать трудности для поисковых роботов. Поэтому важно убедиться, что ваш сайт правильно индексируется. Для этого воспользуйтесь специальными инструментами: «Просмотр как Googlebot» в Google Search Console и «Анализ страниц» в «Яндекс Вебмастере». Они покажут, как поисковые роботы видят ваши страницы, и помогут выявить возможные проблемы с индексацией.
Первое, что стоит сделать, — создать файл robots.txt. У большей части систем управления сайтом (CMS) есть автоматизированные решения для его генерации. Но нужно как минимум понимать, какие директивы используются в этом файле. На скриншоте показан стандартный документ для сайта на WordPress:
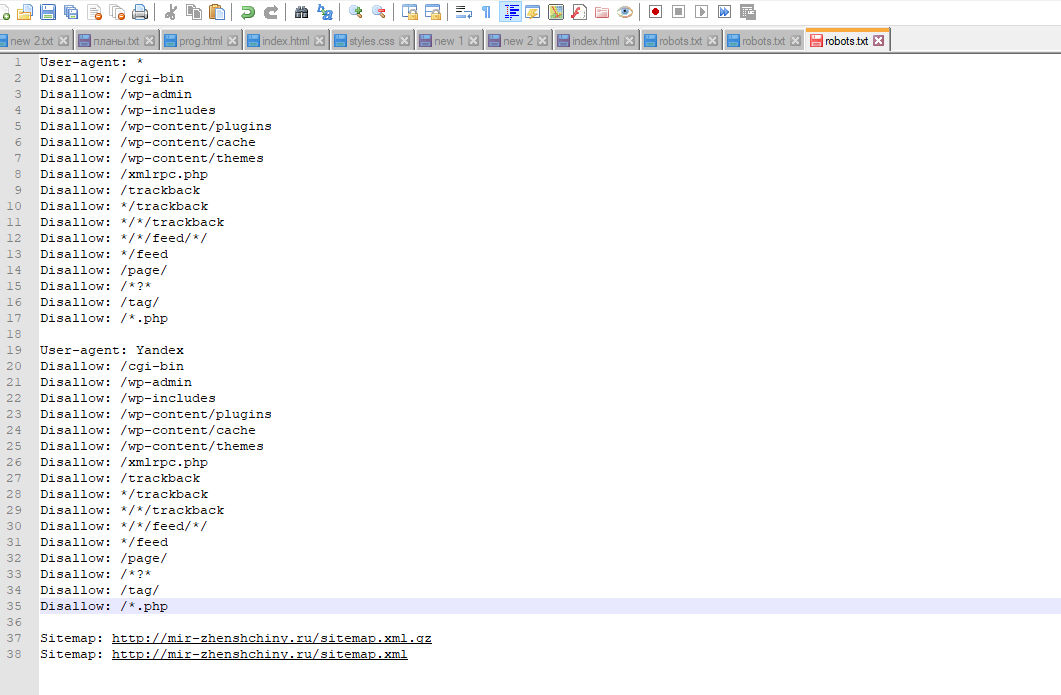
Обратите внимание, что здесь нет директивы host: она не используется «Яндексом» с 2018 года, а Google никогда ее и не замечал. Но при этом до сих пор встречаются рекомендации по использованию этой директивы, и многие по инерции вставляют ее в файл.
В целом правильный синтаксис файла очень важен, ошибки могут привести к сбою индексации. В таблице ниже указаны основные параметры, используемые в robots.txt:
|
Директива |
Зачем используется |
|
User-agent: |
Показывает поискового робота, для которого установлены правила |
|
Disallow: |
Запрещает индексацию страниц |
|
sitemap: |
Показывает путь к файлу sitemap.xml |
|
Clean-param: |
Указывает на страницы, где часть ссылок не нужно учитывать, например UTM-метки |
|
Allow: |
Разрешает индексацию документа |
|
Crawl-delay: |
Указывает поисковому роботу минимальное время ожидания между посещением предыдущей и следующей страницы сайта |
Рассмотрим более подробно код на следующем скриншоте.

User-agent показывает, что директивы предназначены для «Яндекса». А директива Disallow показывает, какие страницы не должны попасть в индекс. Это технические документы, в частности админ-панель сайта и плагины.
Более подробно о том, каким должен быть robots.txt для сайта, можно прочитать в справке сервиса «Яндекс Вебмастер»
Далее делаем файл sitemap.xml для упрощения считывания данных поисковыми роботами: фактически это карта сайта, созданная в формате xml. В файл вносятся все страницы, которые должны быть проиндексированы. В некоторых случаях делаются отдельные карты для видео, картинок и других типов контента.
Для правильной индексации файл не должен превышать 50 Мб или 50 000 записей. Если нужно проиндексировать больше адресов, делают несколько файлов, которые в свою очередь перечисляются в файле с индексом sitemap.
На практике сайты, работающие с бизнесом, редко имеют потребность в подобном решении — просто имейте в виду такую особенность.
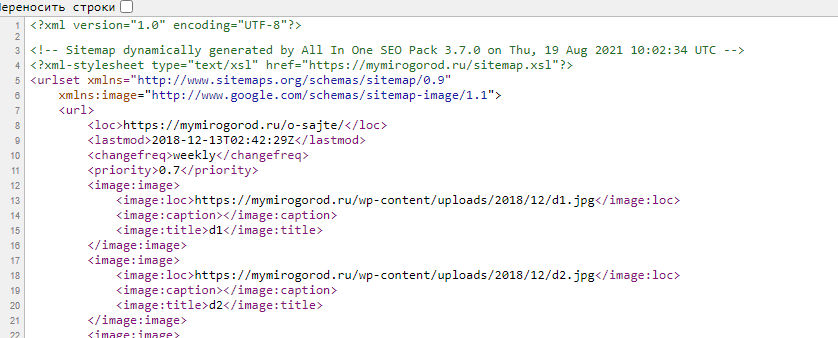
На скриншоте показан фрагмент кода sitemap.xml, сгенерированный одним из плагинов WordPress:
Остается разобраться, как создать файл sitemap.xml. Решение зависит от CMS вашего сайта. Если он сделан не на популярном «движке», придется делать все руками. Можно воспользоваться онлайн-генератором: например, mySitemapgenerator. Вводим адрес сайта и через короткое время получаем готовый файл.
Для сайтов на CMS WordPress сделать такую карту сайта еще проще. У вас все равно уже установлен один из плагинов для SEO-оптимизации ресурса. Заходим в настройки плагина и включаем генерацию sitemap.xml. На скриншоте показан пример включения карты сайта через плагин AIOSEO:
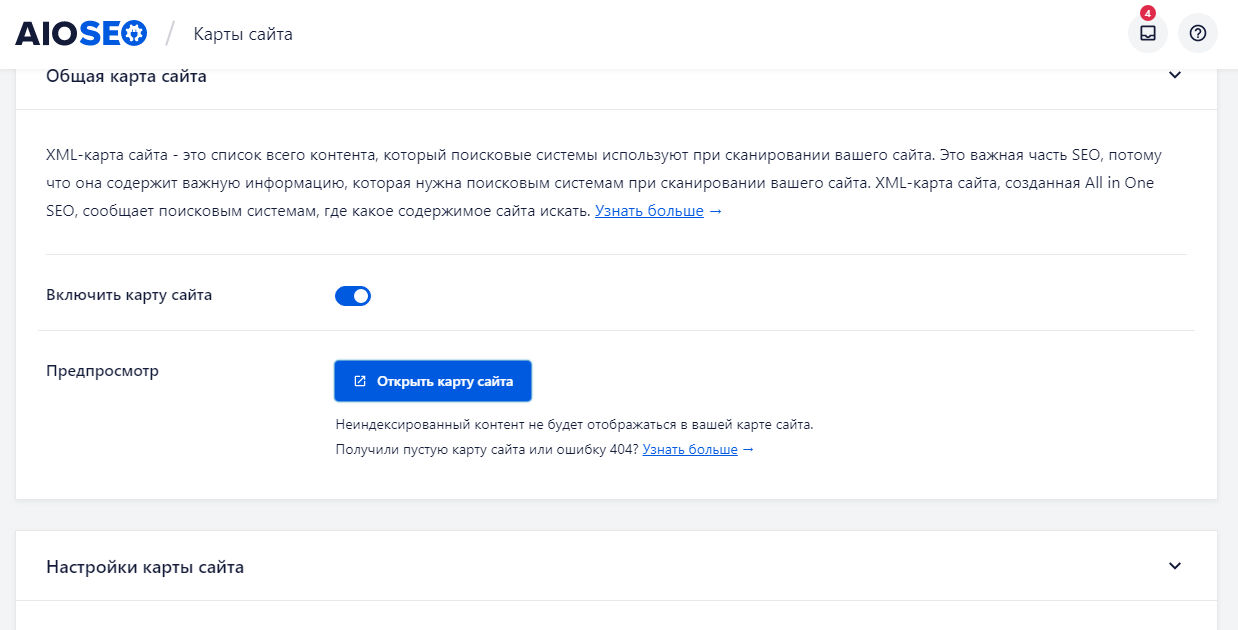
Чтобы сайт максимально быстро индексировался, следует обеспечить перелинковку. Тогда поисковый робот без проблем будет переходить по страницам и своевременно найдет новый документ.
Помимо перечисленного, управлять индексированием можно с помощью мета-тегов. Наиболее известен <meta name=”robots” content=”..., …”>.
По умолчанию в атрибуте content используются параметры: “index, follow”. Это означает открытие ссылки или страницы для индексирования. Если документ нужно закрыть от индексирования применяют параметры “noindex, nofollow”.
Также для Google используется специальный тег <meta name="googlebot" content="..., ...">, задающий инструкции для поискового робота Google. Здесь используются параметры аналогичные мета-тегу robots. У «Яндекса» используется для таких же целей атрибут yandex.
Вместо мета-тегов можно использовать заголовок X-Robots-Tag. Выглядит он так:
HTTP/1.1 200 OK
Date: Tue, 15 May 2025 21:32:43 GMT
X-Robots-Tag: noindex
В этом случае запрещена индексация страницы. Также можно закрыть от индексации определенных элементов страницы, например, закрыть от сканирования поисковыми роботами картинки: X-Robots-Tag: noimageindex.
Далее необходимо выполнить настройку индексирования в «Яндекс Вебмастер» и Google Search Console.
.jpg)
Как ускорить индексацию сайта
В начале статьи мы рассказывали, как настроить индексирование. Теперь поговорим о том, как ускорить это процесс. В целом современные поисковые роботы довольно быстро собирают информацию о ресурсе: по моим наблюдениям, новые страницы появляются в индексе уже через 20–40 минут. Но так бывает не всегда, потому что может произойти сбой или еще какая-то нештатная ситуация, и страница будет индексироваться очень долго.
Появление адреса в списке проиндексированных страниц «Яндекс.Вебмастера» не совпадает с моментом индексации. На практике URL оказывается в индексе намного раньше, а в кабинете только при очередном апдейте.
При этом есть ситуации, когда индексирование нужно ускорить:
- Сайт выходит из-под фильтров.
- Молодой ресурс обладает небольшим краулинговым бюджетом.
- Необходимо быстро проиндексировать большое количество новых или обновленных страниц.
В таких случаях рекомендуется использовать специальные инструменты для ускорения индексации.
- Google Indexing API. Используется для Google Позволяет программно отправлять URL-адреса на индексацию. Подробнее о настройке и использовании этого инструмента можно узнать в нашей статье о Google Indexing API.
- Yandex IndexNow. Аналог для «Яндекса». Это протокол, позволяющий веб-мастерам мгновенно информировать поисковые системы об изменениях на сайте. Использование IndexNow помогает ускорить обнаружение и индексацию новых или обновленных страниц.
- Инструменты для вебмастеров. Для «Яндекса» это функция «Переобход страниц» в «Яндекс Вебмастере», а для Google — инструмент «Запросить индексирование» в Google Search Console. Однако эти методы имеют ограничения по количеству запросов и могут быть менее эффективными для крупных сайтов с частыми обновлениями.
- Sitemap.xml. Правильная настройка этого файла значительно ускоряет процесс индексации.
- Правильная оптимизация сайта. Регулярные и правильные работы с сайтом показывают поисковым системам, что ресурс содержит актуальную информацию, а значит его стоит индексировать в первую очередь.
Разберем на примере, как ускорить процесс индексирования новых документов на сайте. Начнем с «Яндекса» — заходим в «Яндекс Вебмастер» и в меню слева, во вкладке «Индексирование», находим ссылку «Переобход страниц». Переходим по ней:
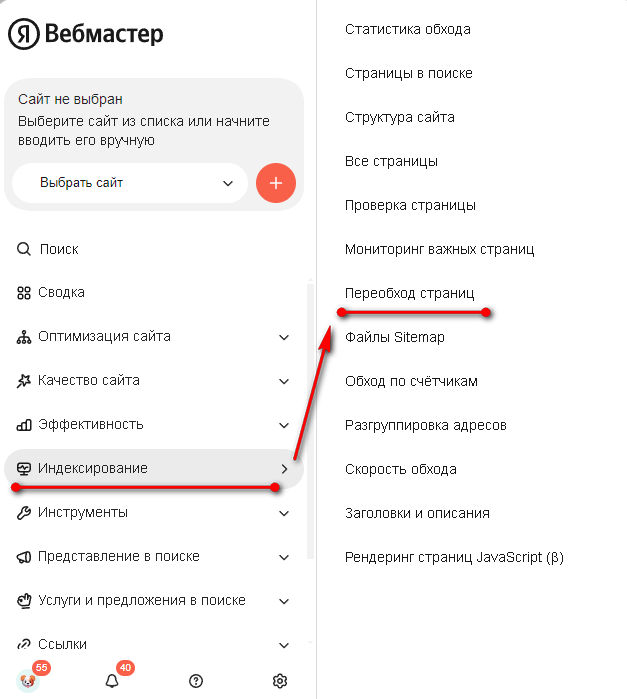
На следующей вкладке вводим URL новой страницы, после чего жмем кнопку «Отправить». Отследить статус заявки можно в расположенном ниже списке:
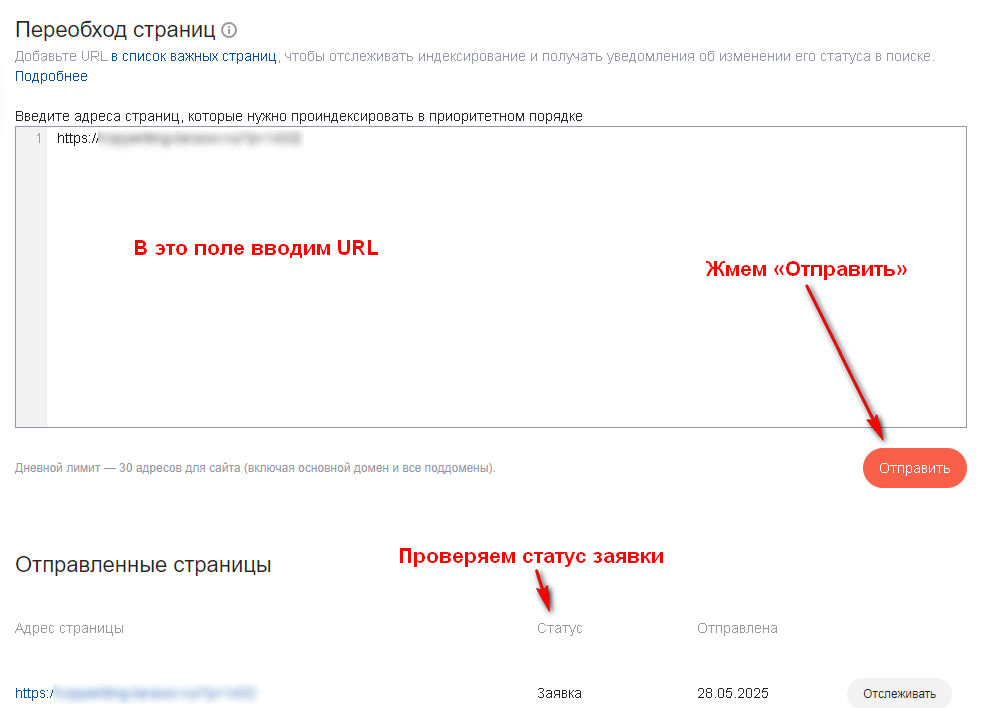
Так можно поступать не только с новыми страницами, но и в случае изменения уже имеющихся на сайте. Только помните, что количество отправок в сутки ограничено, причем все зависит от возраста и траста сайта.
В самом «Вебмастере» предлагается для ускорения индексирования подключать переобход по счетчику «Яндекс Метрики». Это не самое лучшее решение. Дело в том, что поисковый робот может ходить по всем страницам — даже тем, которые не нужно индексировать, причем в приоритете будут наиболее посещаемые документы. Может получиться ситуация, когда старые страницы робот обошел, а новые не заметил. Или вообще в поиск попадут технические страницы: например, страница авторизации или корзина интернет-магазина.
У Google ускорение индексации состоит из двух этапов. Сначала идем в Search Console, где на главной странице вверху находится поле «Проверка всех URL». В него вставляем адрес страницы, которую нужно проиндексировать. Далее нажимаем на клавиатуре «Enter».
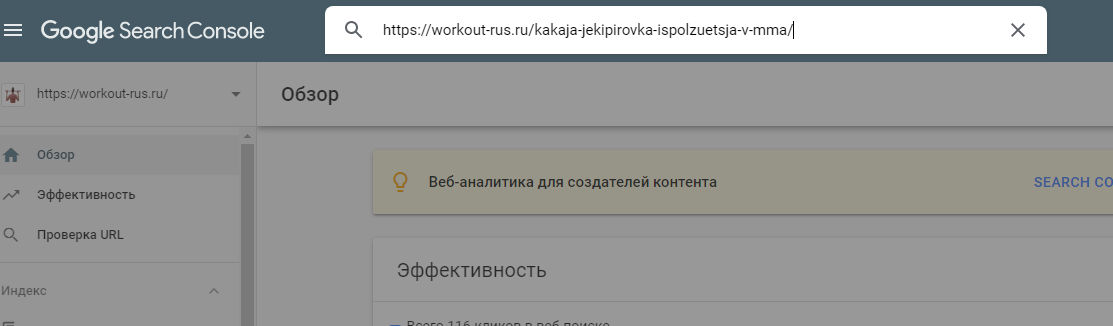
Ждем около минуты. Сервис нам будет показывать вот такое окно:
Следующая страница выглядит вот так:
Некоторое время поисковая машина будет проверять, есть ли возможность проиндексировать адрес:
Если все прошло успешно, Google сообщает, что страница отправлена на индексирование. Остается только дождаться результатов.
При отправке на индексирование страниц сайта, следует помнить, что Google до сих пор очень ценит ссылки.
Раньше рекомендовали сразу после публикации страницы идти в Twitter (сейчас X) и делать твит с нужным адресом. Буквально через полчаса URL будет уже в индексе Google. Сейчас этот метод считается историческим и не дает должного эффекта.
Основным же методом ускорения индексации все-таки стоит назвать регулярную работу над сайтом.
Теперь по пунктам.
Настройте сканирование. Правильная настройка файла robots.txt ускоряет процесс переобхода.
Настройте приоритезацию обхода нужных страниц. Это делается в файле индекса или в карте сайта sitemap.xml. Так вы покажете поисковым роботам какие страницы нужно обходить в первую очередь.
Отправить страницы на переобход. В «Яндекс Вебмастер» инструмент так и называется «Переобход страниц», в Google Search Console есть возможность отправить URL на переобход через форму вверху страницы сервиса. Если страниц много, то для Google можно воспользоваться инструментом Indexing API.
Даем сигналы что страница важная. Для этого на документ должны вести ссылки с главной страницы. Добавьте внешние ссылки, желательно с трастовых ресурсов.
Размер файлов. Если документ у вас тяжелый, то поисковые роботы в целях экономии ресурсов будут обходить их в последнюю очередь. Поэтому, для ускорения индексации необходимо ускорять загрузку страниц сайта.
Правильная перелинковка. Нужно делать ссылки внутри сайта так, чтобы поисковый робот находил их в первую очередь. Естественно внешние ссылки тоже ускоряют процесс индексации.

Как запретить индексирование
В некоторых случаях может потребоваться не проиндексировать, а наоборот запретить индексацию:
- Новая страница без контента. Бывают ситуации, когда страница уже сверстана, а контент еще не готов. В этом случае лучше? чтобы поисковые системы не видели такой документ.
- Результаты внутреннего поиска. Для поисковой системы такие страницы могут показаться не соответствующими требованиям, и сайт может попасть под фильтры.
- Дублирующийся контент и фильтры. В принципе ситуация аналогична предыдущей. Так как контент будет одинаковым и/или переспамлен ключевыми словами по причине сбора на одной странице всех заголовков, лучше скрывать подобные документы от поисковых систем.
- Тестовые версии. Это может быть просто тестовая страница или созданная именно под рекламный трафик. В любом случае лучше их не индексировать.
- PDF и doc-файлы. В них зачастую содержится конфиденциальная информация, чтобы она не попала в поисковую выдачу просто закрываем их от индексации.
К примеру, вы только создаете страницу и на ней нет нужной информации, или вообще сайт в разработке и все страницы — тестовые и недоработанные.
Существует несколько способов, чтобы «спрятать» страницу от поисковых роботов. Рассмотрим наиболее удобные варианты.

Способ первый. Точечное закрытие от индексации
Если вам нужно скрыть всего один документ, можно добавить в код страницы метатег Noindex. Эта команда дает поисковому роботу команду не индексировать документ. Размещают его между тегами <head>. Вот код, который нужно разместить:
<meta name="robots" content="noindex" />
Большая часть CMS позволяют использовать этот метод в один клик, предлагая готовые решения. У WordPress, например, для этого имеется отдельная строчка в настройках редактора, а в «1С-Битрикс» путем настроек раздела и конкретной страницы.
Способ второй. Работа с robots.txt
Заключается в редактировании файла robots.txt. Разберем несколько примеров закрытия страниц от индексирования и начнем с полного закрытия сайта. На скриншоте код, который выполняет эту задачу: звездочка говорит, что правило работает для всех поисковых роботов. Косая черта (слеш) показывает, что директива Disallow относится ко всему сайту.
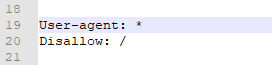
Если нужно закрыть сайт от индексации только в одной поисковой системе — добавляют Disallow только для определенных поисковых роботов.
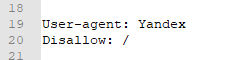
В некоторых случаях есть потребность закрыть от индексации конкретную страницу. Тогда добавляют подобную строчку.

Таким образом, можно довольно гибко управлять индексацией вашего ресурса.
Способ третий. Удаление контента со статусом 404/410
Сначала нужно разобраться с различиями этих статусов. Если речь идет про ошибку 404, она показывает, что контент не смогли найти. Возникает в случае неправильного URL или если страница была удалена. Код ошибки 410 появляется, только если контент был полностью удален с ресурса. Фактически оба статуса показывают примерно одно и то же.
Разница заключается в отношении к этим статусам у поисковых систем. В случае с «Яндексом» обработка страниц с ошибками 404 и 410 не различается. Если на них не будет идти внешних ссылок, со временем они пропадут из индекса. Но, все это время поисковый робот будет их обходить.
У Google подход другой. Поисковый робот различает ошибки 404 и 410. Если он получает от страницы ошибку 410, то сразу удаляет ее из индекса и больше туда не заходит. В случае получения кода 404 краулер возвращается через сутки для проверки. И если получает еще один раз ответ 404, тогда уже удаляет URL из индекса.

Распространенные ошибки индексирования
Перечислю самые популярные ошибки индексирования и некоторые способы их устранения.
- Неправильный robots.txt (случайный Disallow: /). Случайно прописывание в robots.txt директивы закрывающей весь сайт или часть документов от индексации. Устраняется путем удаления этой директивы.
- Неправильные HTTP-заголовки (X-Robots-Tag). Проблема аналогична предыдущей, с той разницей что ошибка происходит не в отдельном файле, а в коде конкретной страницы. Исправляется внесением правок в код документа.
- Ошибки в sitemap.xml (недоступен, неактуален, битые ссылки). Напрямую сказывается на скорости индексирования, а в Google вообще может помешать сканированию сайта. Для устранения нужно исправить процессы создания файла, метод решения проблемы зависит от вашей CMS. В некоторых случаях придется обратиться к программисту.
- Неправильные редиректы (цепочки, 302 вместо 301 надолго). Обычно ошибка заключается в настройке редиректов со старого адреса страницы не на новый, а на главную страницу. Устраняется правильным редиректом со старого документа на новый.
- Ошибки сервера (5xx, таймауты). Это технические проблемы, связанные или с особенностями сайта, или с проблемами серверов. Если поисковый робот сканирует страницу в моменты, когда она отдает 5xx ошибку или загружается с задержкой, он не проиндексирует этот документ. Для решения проблемы придется обратиться к разработчику сайта или администраторам сервера.
- Медленная загрузка сайта. В этом случае поисковые роботы могут помечать ресурс как некачественный, соответственно, реже его сканировать. Решается проблема с помощью ускорения загрузки сайта.
- Проблемы с JS-рендерингом. В этом случае часть контента не отрисовывается при рендеринге и поисковый робот их не видит. Устраняется правильной настройкой индексации JS-кода сайта.
- Заблокированные ресурсы (CSS/JS в robots.txt, мешающие рендерингу). Иногда встречаются ситуации когда разработчик случайно или специально закрыл такие файлы от индексации. В итоге поисковые системы их не могут проиндексировать. Устраняется внесением правок в robots.txt.
- Дублированный контент (без canonical, hreflang). Поисковый робот при наличии дублирующего контента индексирует только одну страницу, обычно посещенную раньше всего. При этом обход всех страниц происходит регулярно. Это приводит к быстрому расходованию краулингового бюджета на дубли. Лучше дублирующий контент или заменить на оригинальный, или закрыть технические дубли от индексирования.
- Малоценный или неуникальный контент. В этом случае сайт скорее всего попадает под фильтр полностью или отдельными страницами. Иногда страницы могут выбрасываться из индекса полностью, в других случаях просто снижаются позиции. В любом случае единственным вариантом решения проблемы можно назвать только переработку контента.
- Каннибализация URL. Фактически это конкуренция отдельных страниц по одному запросу. Постепенно одна страница вытесняет из индекса другую. Устраняется проблема с помощью проработки семантического ядра и правильной кластеризации запросов.
- Отсутствие HTTPS или смешанный контент. Поисковые системы внимательно относятся к безопасности посещаемых страниц. Если на них нет SSL-сертификата или он работает не со всем контентом в документе, поисковый робот пометит такой документ как небезопасный и его индексация будет замедлена или вообще запрещена.
Большая часть перечисленных ошибок решается с помощью разработчиков. Но, иногда требуется вмешательство SEO-специалиста и копирайтера.

Как проверить индексацию сайта
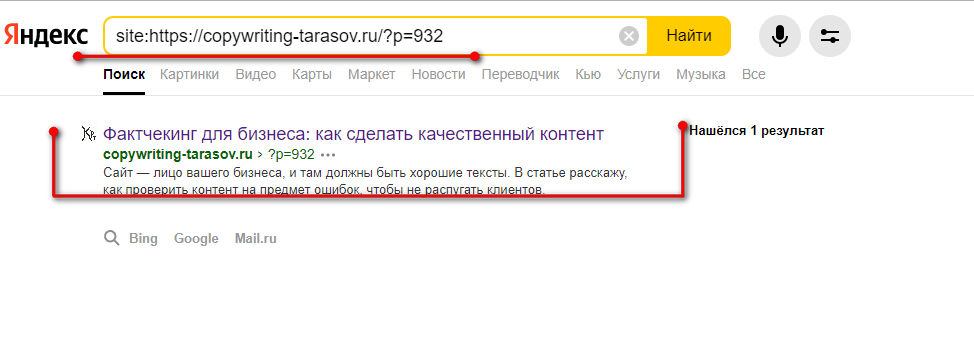
Проверить индексацию сайта можно несколькими способами. Самым простой — в поисковой строке браузера набрать адрес сайта с оператором «site» или «url». Выглядит это вот так: «site: kokoc.com». На скриншоте показан запрос с проиндексированной страницей.
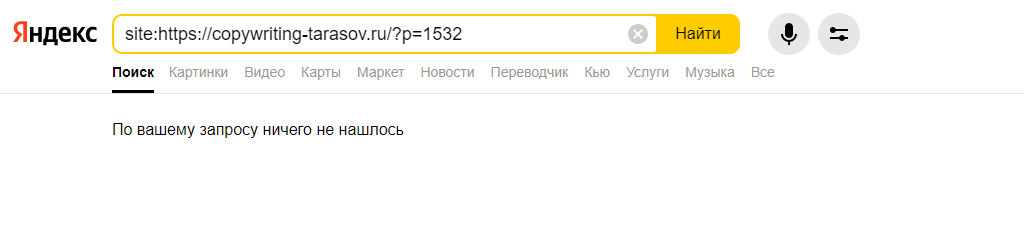
Если страница еще не вошла в индекс, вы увидите вот такую картину. Проверка в Google производится аналогично.
Также можно посмотреть статус документа в «Яндекс Вебмастере». Для этого находим в меню «Индексирование» и переходим на «Страницы в поиске».
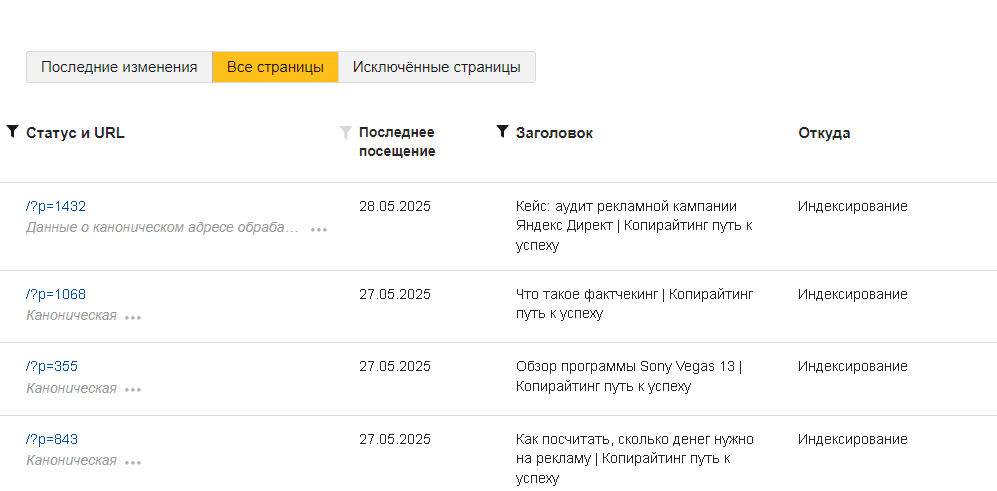
Внизу страницы будут три вкладки. Нас интересуют «Все страницы», там можно увидеть статус документа, последнее посещение и заголовок.
Обязательно посмотрите вкладку «Исключенные страницы». Тут вы увидите, какие документы оказались вне поискового индекса. Также указана причина исключения.
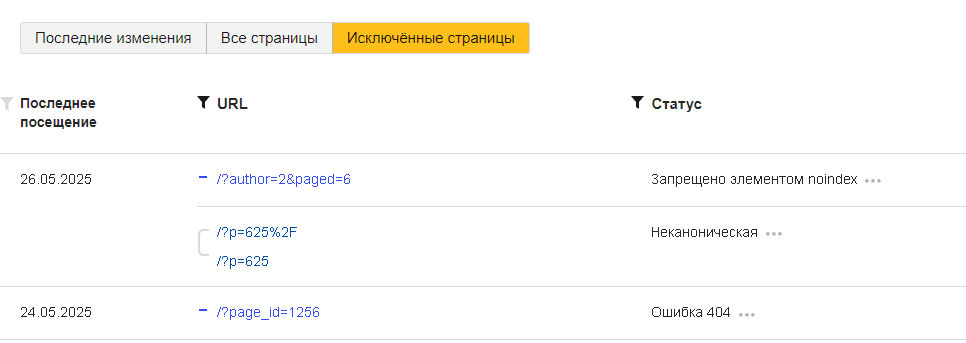
При любых сложностях с индексированием в первую очередь следует смотреть конфигурационные файлы robots.txt и sitemap.xml. Если там все в порядке, проверяем, нет ли фильтров, и в последнюю очередь обращаемся к администратору хостинга.
В Google Search Console проблемы с индексированием можно проверить на вкладке «Индексирование страниц». В самом низу страницы есть список причин проблем с индексацией страниц. Для просмотра проблемных документов жмем на интересующую нас проблему.
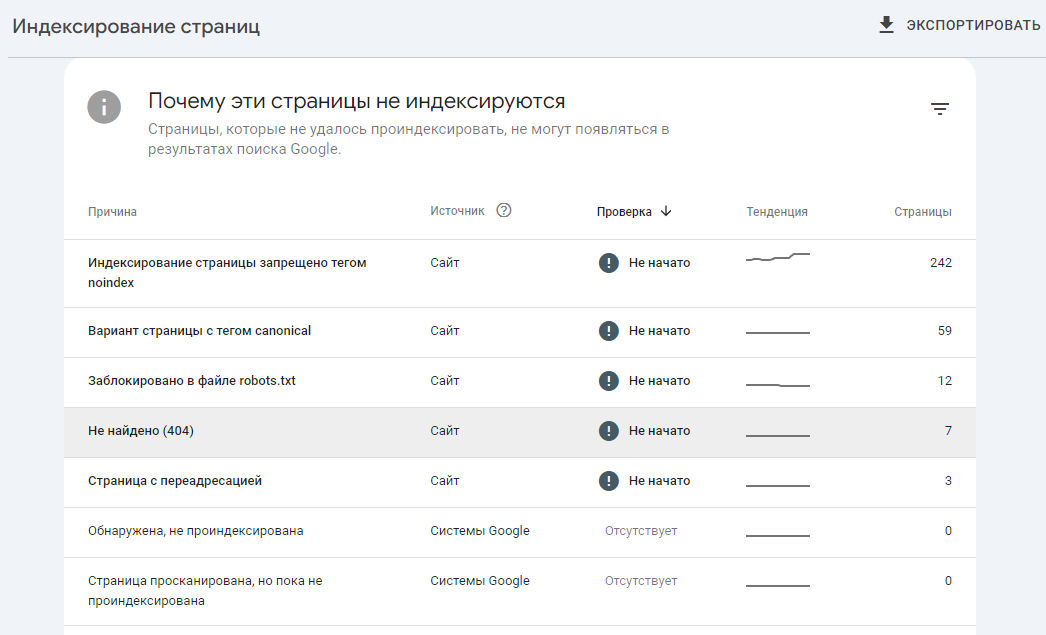
Я выбрал вариант с запретом индексации через тег noindex. Выдается список страниц. Адрес можно скопировать, попробовать открыть страничку (если нужно посмотреть что не проиндексировалось), нажав на «лупу» вы увидите подробности связанные с этим URL.
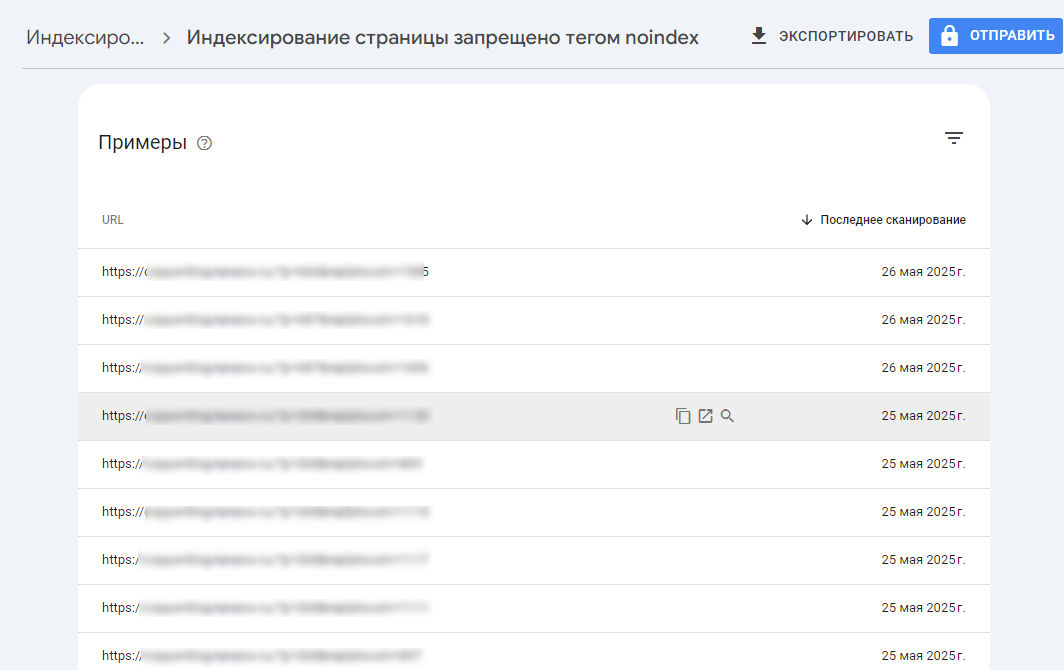
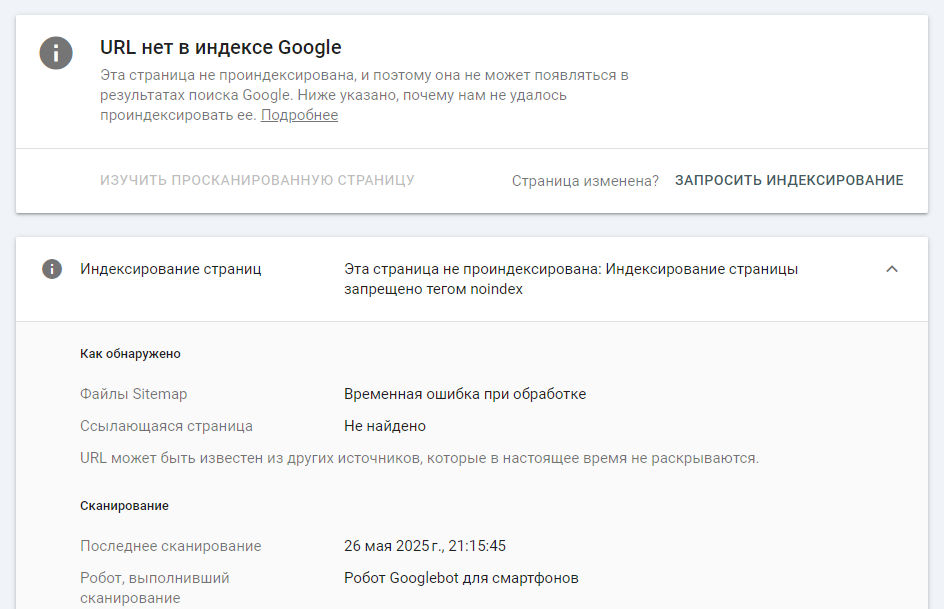
На следующей вкладке можно повторно запросить индексирование. Но, лучше сначала посмотреть отчет. Там указаны источники по которым поисковый робот находит эту страничку, дата сканирования, тип поискового робота, причины ошибки.
Для более глубокого анализа индексации можно использовать API поисковых систем. Google предоставляет URL Inspection API, который позволяет программно проверять статус индексации URL. Яндекс также предлагает API «Яндекс Вебмастера», с помощью которого можно автоматизировать процесс проверки индексации большого количества страниц.
Если вы имеете доступ к log-файлам сервера, можно посмотреть как сканируются разные каталоги сайта. Какие поисковые роботы посещают ресурс и насколько полно проводится сканирование.

FAQ по индексации сайтов
Ниже вы найдете ответы на самые распространенные вопросы про индексацию сайтов.
«Яндекс Вебмастер» не может найти robots.txt. Что делать?
Скорее всего, у вас закрыты для посещения некоторые технические страницы. В частности файл robots.txt. Попросите разработчика посмотреть log-файлы и найти причину закрытия этого файла от переобхода.
В Google Search Console появился запрет noindex, в «Яндекс» все хорошо. Как быть?
Вероятно, где-то в мета-тегах прописан noindex для Googlebot. На скриншоте показан пример такого мета-тега в исходном коде страницы. Проверьте на своем сайте, какие параметры для этих атрибутов прописаны.

Если находится такой атрибут для Googlebot, нужно самостоятельно или с помощью программиста убрать эту проблему.
Что делать если дубли страниц все равно попадают в Sitemap.xml?
Посмотреть в Google Search Console как помечаются эти страницы в отчете «индексирование страниц». Если показано, что это копия, лучше убрать их из Sitemap.xml. В случае, когда они не попадают в отчет, можно ничего не трогать.
Коротко о главном
- Правильная настройка индексации сайта позволяет получать больше трафика.
- При настройке индексирования ресурса необходимо учитывать ключевые аспекты сканирования поисковыми роботами сайта.
- Если ресурс сделан без ошибок, индексирование произойдет без проблем.
- В некоторых случаях необходимо запрещать индексацию. Для этого есть несколько методов.
- Для проверки и ускорения индексации используют инструменты вебмастера, предоставляемые самими поисковыми системами.

.png)

.png)
.png)

Комментарии (2)
Оставить комментарий