

Когда-то я получил задачу выяснить, почему сайт клиента не дает результат в SEO и не получает трафик. Причину нашел быстро: продвижение блокировал всего один текстовый документ.
Теперь я убежден, что каждому специалисту нужно знать техническую базу.
- Что такое файл robots.txt
- Зачем нужен robots.txt
- Синтаксис и директивы
- Robots.txt и другие инструменты управления индексацией
- Как создать robots.txt
- Быстрый старт: базовый шаблон robots.txt
- Шаблоны robots.txt для популярных CMS
- Как запретить сканирование в robots.txt
- Стратегия: что закрывать, а что нельзя
- Управление ИИ-ботами в 2026 году
- Сервисы проверки robots.txt
- ТОП-5 критических ошибок в robots.txt
- Часто задаваемые вопросы о robots.txt
Что такое файл robots.txt
Robots.txt — это текстовый файл с инструкциями для поисковых роботов: какие страницы и разделы сайта им разрешено сканировать, а какие — нет.
Несколько ключевых фактов, которые необходимо учитывать при настройке:
- файл управляет сканированием, а не индексацией напрямую (закрытый URL может попасть в индекс при наличии внешних ссылок);
- документ не защищает конфиденциальный контент (закрытая директория доступна пользователям по прямой ссылке);
- для удаления из выдачи используют мета-тег noindex, а не только правило Disallow;
- файл размещается в корневом каталоге и доступен по адресу yoursite.com/robots.txt;
- отдельный документ создается для каждого домена и поддомена.
Этот настроенный файл robots.txt размещается в корневом каталоге ресурса:
Структурно содержимое состоит из блоков правил. Каждый начинается с директивы User-agent, затем идут Disallow и Allow. Блоки разделяет пустая строка.
У каждой поисковой системы есть специфические требования к синтаксису:
Документ всегда можно отредактировать: закрыть от краулеров новые служебные страницы, административную панель или разделы с дублями.
Для этого нужно получить доступ к серверу по FTP, открыть файл в текстовом редакторе («Блокнот», Notepad++, Sublime) и внести правки. После — сохранить в кодировке UTF-8 и скопировать в корень сайта с заменой старой версии. Обязательно проверьте результат, открыв mysite.com/robots.txt в браузере.
Будет не лишним прогнать код через валидаторы: о них поговорим далее.

Зачем нужен robots.txt
- управление перечнем страниц для обхода поисковиками;
- снижение нагрузки на хостинг при сканировании;
- указание пути к карте сайта (sitemap.xml);
- экономия краулингового бюджета — перераспределение ресурса на важный контент;
- закрытие служебных разделов: админки, корзины, результатов поиска;
- составление инструкций для конкретных ботов.
Если директивы прописаны корректно, но поисковик их игнорирует, проверьте технические параметры:
- Размер превышает лимит. Яндекс поддерживает документы до 500 КБ, Google — до 500 КБ.
- Кодировка отличается от UTF-8.
- Формат не текстовый. Расширение строго
.txt, название в нижнем регистре. - Сервер не отдает HTTP-статус 200 OK.
Необходимо регулярно проверять доступность документа и валидность его содержимого.

Синтаксис и директивы
Синтаксис включает обязательные директивы (User-agent, Disallow, Allow) и дополнительные (Sitemap, Clean-param).
Рекомендуемый порядок внутри блока: сначала User-agent, затем запрещающие и разрешающие правила. Блоки разделяются пустой строкой.
Самое важное — не допускать ошибок. В начале статьи я упоминал один символ, который обнулил SEO. Это директива «Disallow: /», закрывшая весь ресурс от краулеров. Так часто делают при разработке, но забывают убрать на проде.
Главное — после релиза открыть проект для сканирования полностью или поставить запрет только на технические URL.
Базовые правила работы с синтаксисом:
- Одна строка содержит одну директиву.
- Правило начинается с новой строки без пробелов в начале.
- Параметр нельзя переносить.
- Название файла пишется строго в нижнем регистре (robots.txt), регистр самих директив не важен.
- Перед папками ставится прямой слэш (/): например,
/category. - Используется латиница.
- Пустая строка разделяет блоки для разных краулеров.
Спецсимволы в директивах
В значениях Allow и Disallow допускаются специальные знаки:
*(звёздочка) — маска, заменяет любую последовательность символов в URL. Например,Disallow: */catalog/sort-*закроет адреса с этим фрагментом.$— фиксирует конец строки. Например,Disallow: /*.pdf$закрывает документы, оканчивающиеся на.pdf.#— задает комментарий. Информация после него игнорируется роботом.
Приоритет Allow и Disallow
При конфликте правил Googlebot выбирает директиву с более длинным путем. При равной длине приоритет отдается Disallow. Роботам Яндекса важна конкретика: более точное указание перекрывает общее.
Пример, где Allow побеждает благодаря длине пути:
Disallow: */notebooks
Allow: */notebooks/gamers
# страница /notebooks/gamers будет доступна, так как Allow длиннее
Основные директивы:
-
User-agent. Указывает адресата правил. Прописывается в первой строке блока:
User-agent: *
# обращение ко всем поисковым системам
User-agent: Yandex
# обращение только к краулеру Яндекса
-
Disallow. Запрещает сканирование каталога или документа:
User-agent: *
Disallow: /category
# закрыт обход раздела и вложенных страниц
-
Allow. Разрешает обход конкретных адресов:
User-agent: *
Allow: /
# разрешён обход всего сайта
-
Clean-param. Указывает Яндексу не учитывать динамические параметры (UTM-метки, сортировки), чтобы исключить дубли:
Clean-param: utm # применяется к параметрам по любому адресу
-
Crawl-delay. Задает таймаут между запросами. Яндекс поддерживает значения до 2 секунд. Googlebot игнорирует этот параметр (настройка доступна в Search Console):
User-agent: YandexBot
Crawl-delay: 2
# пауза 2 секунды между запросами
-
Host. Устаревшая инструкция для указания главного зеркала. С 2018 года не учитывается Яндексом и Google. Добавлять не нужно.
-
Sitemap. Показывает путь к XML-карте. Прописывается в конце документа:
Sitemap: https://yoursite.com/sitemap.xml
Robots.txt и другие инструменты управления индексацией
Разница между robots.txt и смежными инструментами принципиальна. Их путаница приводит к потере трафика.
| Инструмент | Уровень воздействия | Управляет | Типичный кейс |
|---|---|---|---|
| robots.txt | Файл на сервере | Сканированием (crawling) | Закрыть от обхода админку, служебные разделы, UTM-параметры |
| Meta robots (noindex) | HTML-код страницы | Индексацией страницы | Убрать страницу из выдачи, оставив доступ для робота |
| X-Robots-Tag | HTTP-заголовок | Индексацией любого ресурса | Запретить индексацию PDF, изображений — там, где нет HTML |
| Canonical | HTML-код страницы | Приоритетной версией дублей | Указать основную страницу при дублировании контента |
Страница с Disallow может попасть в индекс при наличии внешних ссылок. Для полного удаления из выдачи применяют мета-тег noindex в HTML-коде или X-Robots-Tag: noindex в HTTP-заголовке.
Disallow экономит краулинговый бюджет на этапе планирования, а X-Robots-Tag требует полной загрузки документа сервером.
%201.png)
%201.png)
%201.png)
%201.png)
%201.png)
Как создать robots.txt
Сформировать код можно двумя способами.
Вручную
Создаём пустой текстовый документ и прописываем базовые строки:
User-agent: *
Disallow: /wp-admin/
# не сканировать адрес административной панели WordPress
Disallow: /privacy-policy/
# не сканировать страницу с политикой конфиденциальности
Sitemap: https://yoursite.com/sitemap.xml
# путь к карте сайта
Часто вебмастера оставляют служебные комментарии:
User-agent: *
Allow: /
# Саня, если клиент не заплатит, через три дня загоняем весь сайт под запрет!
Автоматически
Генераторы помогают сформировать правильный синтаксис без ручного ввода.
После ввода настроек получаем готовый код:
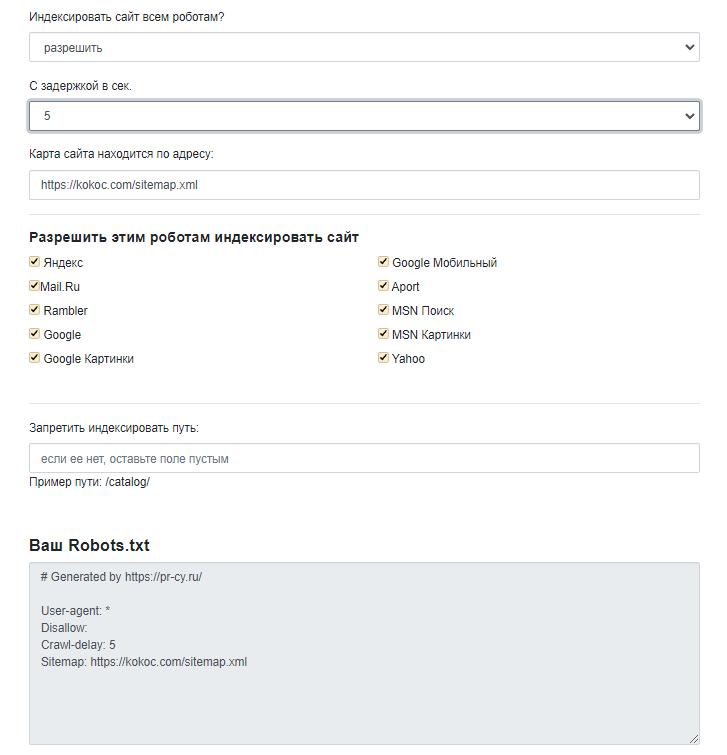
На реальном проекте всегда нужно учитывать специфику CMS при закрытии разделов.
Выбираем «Инструменты» → «Генераторы» → «Генератор robots.txt». Указываем адрес, робота, папки для блокировки. Текст формируется в режиме реального времени.
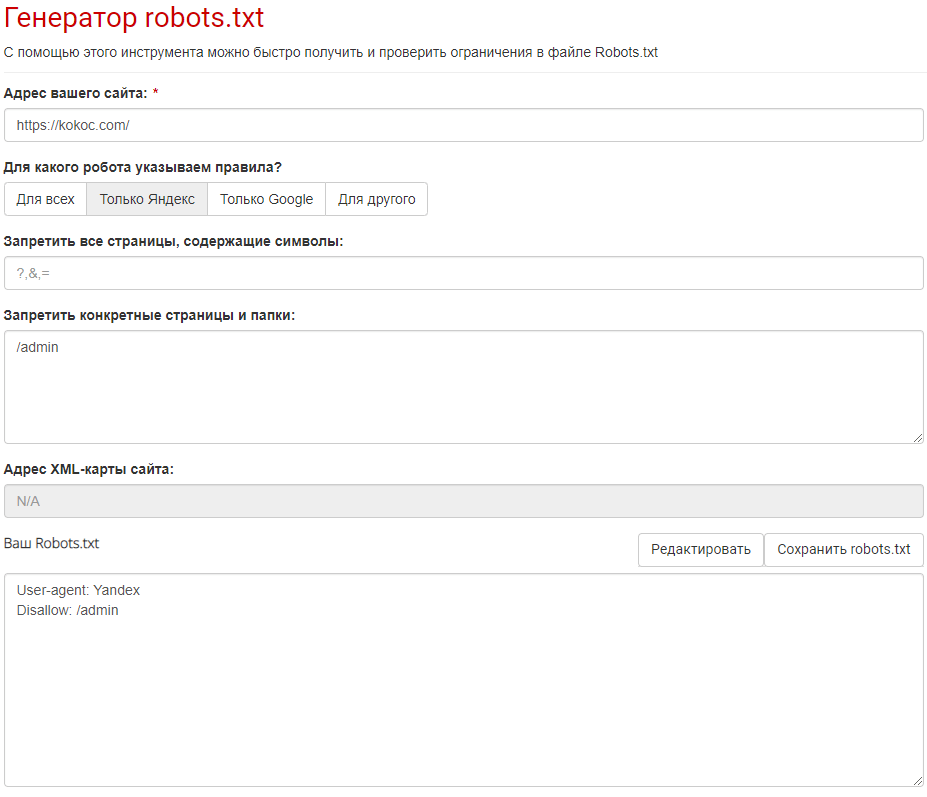
В футере находим «Онлайн-сервисы» → «Генератор Robots.txt».
Вводим домен, User-agent, выбираем страницы для запрета и путь к sitemap.xml:

Сервис выдает подробную инструкцию по внедрению полученного кода.
Быстрый старт: базовый шаблон robots.txt
Этот универсальный вариант закрывает типовые служебные страницы, но оставляет доступ к CSS и JS.
User-agent: *
Disallow: /admin/
Disallow: /login/
Disallow: /search/
Disallow: /cart/
Allow: /*.css
Allow: /*.js
Sitemap: https://example.com/sitemap.xml
Блокировка стилей и скриптов мешает поисковику увидеть дизайн и оценить контент, что снижает позиции.
Шаблоны robots.txt для популярных CMS
Разные платформы генерируют разные служебные URL.
WordPress
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/cache/
Disallow: /wp-json/
Disallow: /xmlrpc.php
Disallow: /?s=
Allow: /wp-content/uploads/
Allow: /*.css
Allow: /*.js
Sitemap: https://yoursite.com/sitemap.xml
Строка Allow: /wp-admin/admin-ajax.php нужна при использовании AJAX-запросов.
1С-Битрикс
User-agent: *
Disallow: /bitrix/
Disallow: /personal/
Disallow: /search/
Disallow: /auth/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/css/
Allow: /*.css
Allow: /*.js
Sitemap: https://yoursite.com/sitemap.xml
Если закрыть папку /bitrix/, не разрешив CSS и JS, поисковые системы некорректно воспримут мобильную версию.
Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /components/
Disallow: /modules/
Allow: /*.css
Allow: /*.js
Sitemap: https://yoursite.com/sitemap.xml
Интернет-магазин (универсальный шаблон)
User-agent: *
Disallow: /cart/
Disallow: /checkout/
Disallow: /account/
Disallow: /login/
Disallow: /search/
Allow: /*.css
Allow: /*.js
User-agent: YandexBot
Clean-param: utm_source&utm_medium&utm_campaign&utm_content&utm_term /catalog/
Sitemap: https://yoursite.com/sitemap.xml
Директива Clean-param исключает дублирование страниц каталога из-за UTM-меток.
%201.png)
Как запретить сканирование в robots.txt
Инструмент позволяет закрыть ресурс полностью или частично.
Если требуется, чтобы правило распространялось на всех ботов, используйте знак звёздочки (*). Для конкретного краулера укажите его название.
Как запретить сканирование всего сайта
User-agent: *
Disallow: /
# запрещён доступ ко всем страницам
Как закрыть страницу от сканирования
User-agent: Googlebot
Disallow: /page
# запрещён доступ роботу Google ко всем URL, начинающимся на "/page"
Стратегия: что закрывать, а что нельзя
Правильная настройка — это управление краулинговым бюджетом. Закрывая мусорные URL, вы направляете ботов на приоритетный контент.
| Закрывать от сканирования | Не закрывать |
|---|---|
| Административная панель (/admin/, /wp-admin/) | CSS-файлы (/*.css) |
| Страницы авторизации (/login/, /auth/) | JS-файлы (/*.js) |
| Корзина и оформление заказа (/cart/, /checkout/) | Шрифты и медиафайлы, нужные для рендеринга |
| Результаты поиска по сайту (/search/, /?s=) | Главная страница и приоритетные разделы каталога |
| URL с UTM-параметрами (через Clean-param для Яндекса) | Страницы товаров и категорий в интернет-магазине |
| Дублирующиеся страницы с параметрами фильтрации и сортировки | Страницы, которые должны ранжироваться в поиске |
| Служебные файлы CMS (/bitrix/, /wp-includes/) | Sitemap.xml (путь к нему указывается в файле) |
Основной принцип: всегда оставляйте открытыми CSS, JS и шрифты. Без них краулер не оценит Core Web Vitals.
Управление ИИ-ботами в 2026 году
Нейросети активно парсят интернет для обучения языковых моделей. Вы можете ограничить им доступ.
Основные User-agent ИИ-ботов:
GPTBot— краулер OpenAI (ChatGPT);Google-Extended— агент Google для обучения моделей Gemini;ClaudeBot— краулер Anthropic (Claude);PerplexityBot— краулер поисковика Perplexity AI;CCBot— краулер Common Crawl.
Пример блока для запрета доступа:
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: CCBot
Disallow: /
Учитывайте, что файл дает лишь рекомендации. Добросовестные парсеры соблюдают правила, но для надежной защиты конфиденциальной информации используйте серверные ограничения (авторизацию, rate limiting).
Сервисы проверки robots.txt
Рассмотрим инструменты на примере сайта kokoc.com.
Яндекс.ВебмастерПереходим в «Инструменты» → «Анализ robots.txt». Вводим адрес и получаем данные:
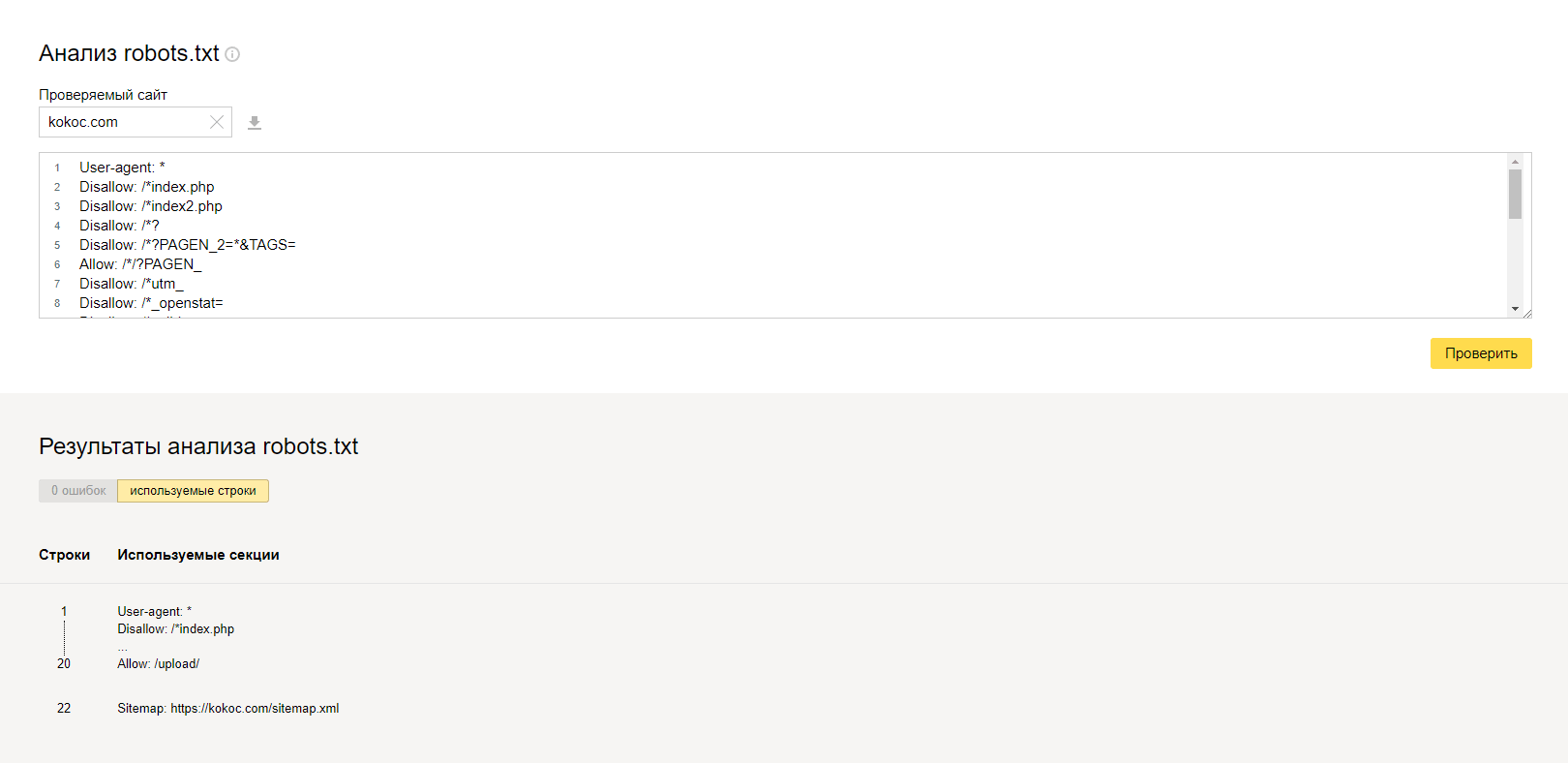
Ошибок нет.
Google Search ConsoleСервис предлагает выбрать объект проверки из подтвержденных ресурсов:
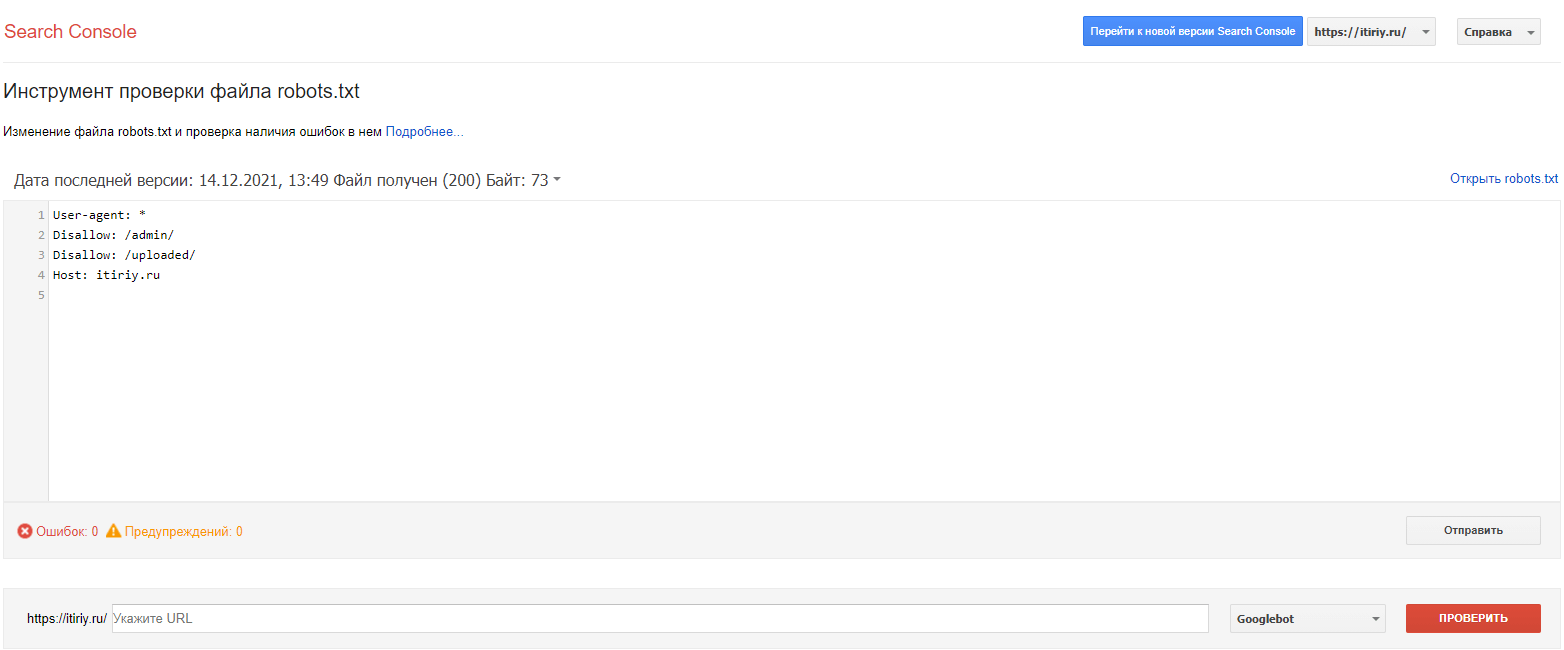
Проверка прошла успешно.
В меню выбираем «Инструменты» → «Все инструменты» → «Анализ robots.txt». Вводим целевой URL:
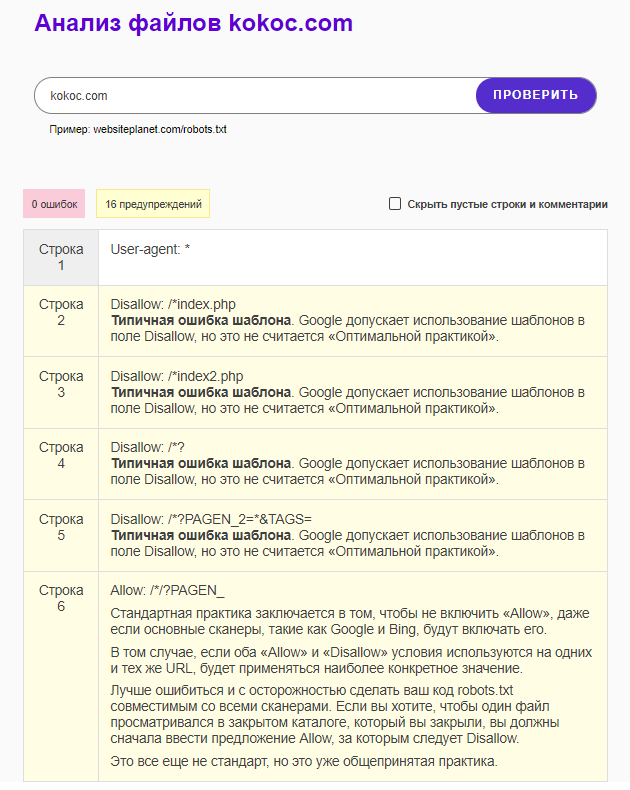
Максимально информативный отчет.
Выбираем robots.txt Tester. Вводим URL, выбираем User-agent. Доступен режим редактирования:
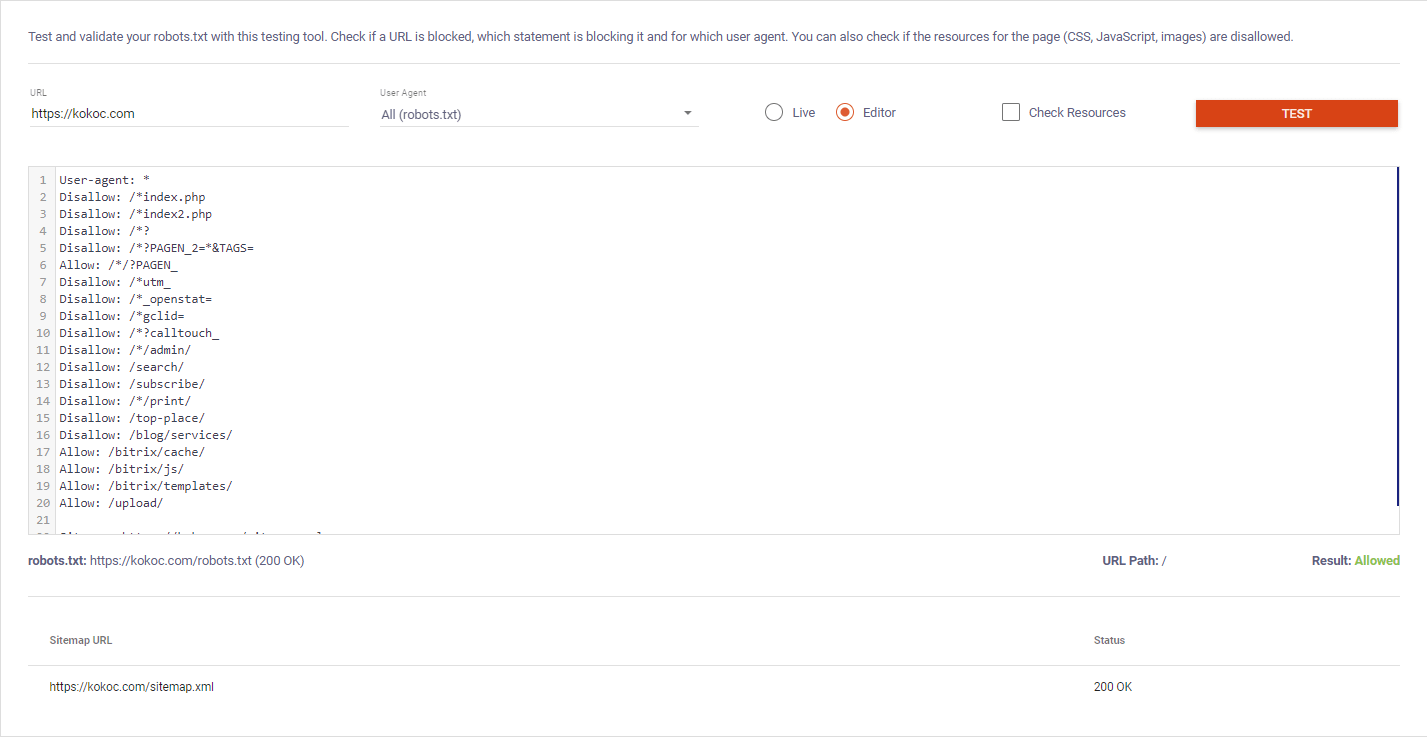
Сервис показывает путь к карте сайта и её статус.
Выбираем «Технический аудит» → «Проверка файла robots.txt».
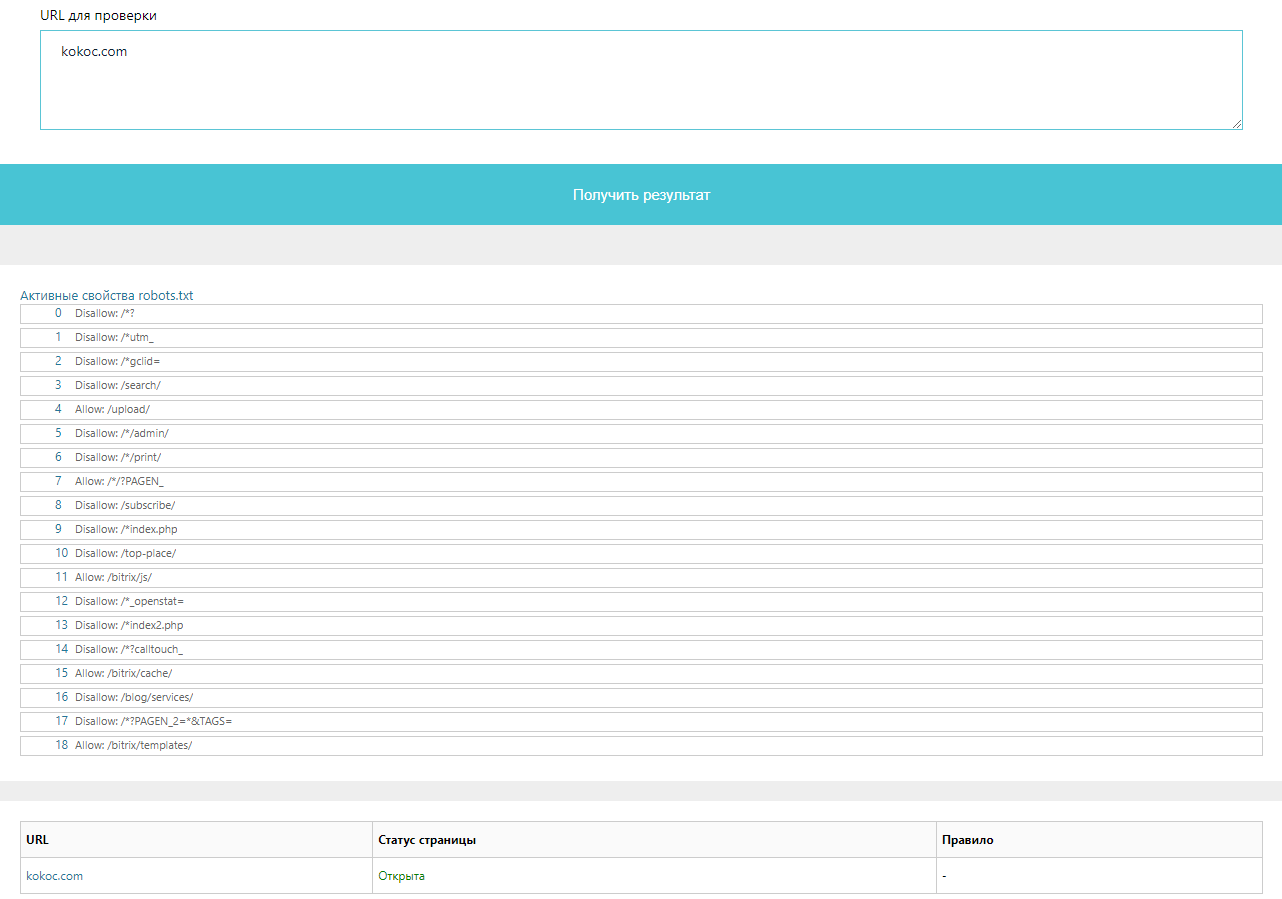
Можно выбрать целевую CMS для проверки соответствующих директив.
ТОП-5 критических ошибок в robots.txt
Проблемы с индексацией часто начинаются здесь. Чек-лист для проверки:
- Disallow: / на продакшне. Весь сайт закрывается от сканирования. Проверяйте код сразу после релиза.
- Блокировка CSS и JS. Поисковый робот не сможет корректно отрисовать дизайн. Всегда явно разрешайте эти ресурсы через Allow.
- Имя файла в неправильном регистре. Документ должен называться строго
robots.txt. - Закрытие раздела вместо конкретной страницы. Если нужно закрыть только страницу
/page, добавьте символ$в конце:Disallow: /page$. - Отсутствие директивы Sitemap. Всегда прописывайте полный URL:
Sitemap: https://yoursite.com/sitemap.xml.
Помните о роботах!
Грамотная настройка экономит ресурсы хостинга и ускоряет продвижение. Поисковые системы лояльны к проектам, соблюдающим технические стандарты.

Часто задаваемые вопросы о robots.txt
Что будет, если файла robots.txt нет на сайте?
Сайт будет индексироваться. Только поисковые роботы будут обходить его хаотично, без учёта важности страниц. В результате технические страницы могут оказаться в индексе, а приоритетные разделы — нет. Для небольших сайтов без служебных разделов это не критично, но для интернет-магазинов и крупных проектов отсутствие файла — это риск потери краулингового бюджета.
Удалит ли Disallow страницу из поисковой выдачи?
Нет. Disallow запрещает сканирование, но не гарантирует удаление из индекса. Если на закрытую страницу ведут внешние ссылки, поисковик может знать о её существовании и показывать её в выдаче без описания. Чтобы убрать страницу из результатов поиска, нужно использовать мета-тег noindex в коде страницы или X-Robots-Tag в HTTP-заголовке.
Могут ли правила robots.txt конфликтовать между собой?
Да. Когда одна страница попадает одновременно под Allow и Disallow, поисковики применяют разные приоритеты. Google отдаёт предпочтение более длинному пути. При одинаковой длине побеждает Disallow. Яндекс учитывает точность указания пути: более конкретная директива имеет приоритет над общей. Чтобы избежать конфликтов, проверяйте каждый URL в инструменте анализа robots.txt в Яндекс.Вебмастер или Google Search Console.
Нужен ли отдельный robots.txt для поддоменов?
Да. Файл robots.txt действует в рамках одного домена. Для каждого поддомена (например, blog.yoursite.com или shop.yoursite.com) нужен собственный файл, размещённый в корне этого поддомена.
Как часто нужно проверять robots.txt?
Проверять файл нужно после каждого значительного изменения на сайте: смены CMS, редизайна, добавления новых разделов, миграции на другой домен. Особенно важно проверить файл сразу после запуска — именно тогда чаще всего забывают снять запрет Disallow: /, оставшийся с тестового окружения. Для регулярного мониторинга используйте инструменты Яндекс.Вебмастер и Google Search Console.
Обязаны ли ИИ-боты соблюдать правила robots.txt?
Robots.txt носит рекомендательный характер. Большинство добросовестных ИИ-краулеров (GPTBot, Google-Extended, ClaudeBot) соблюдают его правила. Однако некоторые парсеры стандарт игнорируют. Если защита контента от ИИ-ботов критична, robots.txt нужно дополнять серверными мерами: блокировкой по User-agent, rate limiting или авторизацией.




.png)

.png)
.png)

Комментарии (12)
Оставить комментарий