

Файл robots.txt — текстовый инструмент, который позволяет управлять индексацией сайта. Он указывает поисковым системам, по каким ссылкам разрешено переходить, а какие служебные разделы стоит заблокировать для обхода. Правильная настройка robots.txt помогает косвенно управлять краулинговым бюджетом интернет-ресурса, что критично для SEO-продвижения. В этой статье разобраны частые ошибки, допускаемые при создании документа, и технические нюансы корректной оптимизации.
- Быстрый чек-лист: что проверить за 60 секунд
- Основы robots.txt: технические требования, которые нельзя игнорировать
- Полный разбор всех директив robots.txt
- ТОП-15 ошибок в robots.txt, которые убивают трафик
- Правильный и неправильный синтаксис
- Шаблоны robots.txt для разных типов сайтов
- Как проверить robots.txt на ошибки
- Восстановление после ошибок и профилактика
- FAQ по robots.txt
- Заключение
- Коротко о главном
Быстрый чек-лист: что проверить за 60 секунд
Прежде чем изучать директивы и типичные ошибки — стоит пробежаться по этому списку. Если хотя бы один пункт не выполнен, трафик и результаты поиска уже под угрозой.
- Файл отдаёт HTTP-ответ 200 OK и Content-Type: text/plain — без редиректов и цепочек переадресации. Откройте браузер или любой онлайн-сервис проверки заголовков и убедитесь в этом.
- Отсутствует строка
Disallow: /для User-agent: * — иначе весь сайт закрыт от индексации для всех роботов. - CSS, JS и шрифты доступны — проверьте, что папки /assets/, /static/, /wp-includes/, /bitrix/css/ открыты.
- Директива sitemap содержит абсолютный URL (например,
Sitemap: https://example.com/sitemap.xml). Если карт несколько — каждую нужно указать отдельной строкой. - Маски * и $ не перекрывают важный контент — каталог, карточки товаров, блог.
- Название написано строчными буквами — robots.txt, а не ROBOTS.TXT.
- Кодировка UTF-8 без BOM — BOM-маркер ломает обработку директив роботами.
- После деплоя изменений необходимо сбросить кэш CDN (при наличии) и запросить повторное сканирование в Search Console или «Яндекс Вебмастере».
Основы robots.txt: технические требования, которые нельзя игнорировать
Что такое robots.txt? Это обычный текстовый документ, который задает правила сканирования сайта поисковыми ботами. Файл управляет обходом, но не выступает инструментом безопасности: он не скрывает контент от пользователей и не ограничивает прямой доступ к URL. Для реальной защиты закрытых данных применяют авторизацию или фильтрацию по IP.
При необходимости заблокировать работу краулеров, важно убедиться в корректности настроек. Это особенно критично при использовании динамических URL, генерирующих бесконечное количество страниц.


Документ можно использовать для множества целей:
- Блокировка сканирования определенных страниц. Они могут появляться в выдаче, но без текстового описания. Контент не в формате HTML тоже не будет сканироваться.
- Запрет индексации медиафайлов. Под медиафайлами понимаются изображения, видео и аудио. Приватный контент не попадет в поиск.
- Блокировка файлов ресурсов с неважными внешними скриптами. Если у страницы закрыт файл ресурсов, поисковые системы посчитают, что его не существовало. Это сказывается на индексировании.
Использование robots.txt не позволит полностью запретить отображение страницы в результатах. Для этого придется добавить метатег noindex в код страницы или использовать HTTP-заголовок X-Robots-Tag.
В таблице представлены основные технические требования к созданию файла:
Параметр |
Значения |
Формат файла |
.txt |
Кодировка |
UTF-8 без BOM |
Расположение |
Корневая директория сайта |
Отклик сервера |
200 OK, Content-Type: text/plain, без редиректов |
Максимальный размер (Googlebot) |
до 500 КБ |
Максимальный размер (YandexBot) |
до 32 КБ — при превышении Яндекс считает весь контент открытым |
У Google и Yandex разные лимиты на размер. Googlebot обрабатывает до 500 КБ, а YandexBot — не более 32 КБ. Если размер превышает этот порог для Яндекса, робот может посчитать весь сайт открытым. На практике стоит держать robots.txt максимально компактным.
Все кириллические домены .ru или .рф должны вписываться с помощью Punycode. В путях применяется корректное URL-кодирование (percent-encoding): кириллические буквы в путях недопустимы.
Полный разбор всех директив robots.txt
Документ содержит команды для краулеров. Ниже разобран синтаксис и структура групп правил.
User-agent: для кого пишем правила
В первую очередь нужно показать, для какого бота написана инструкция. Для этого используется директива User-agent. В таблице показано соответствие значений и поисковых систем:
Поисковая система |
Возможные значения User-agent |
Googlebot, Googlebot-Image, Googlebot Mobile |
|
«Яндекс» |
YandexBot, YandexImages, YandexMobileBot |
Microsoft Bing |
Bingbot |
Mail.ru |
Mail.Ru |
Google Ads |
AdsBot-Google |
Google AdSense |
Mediapartners-Google |
Директива располагается перед группой правил, на которые действует. Это показано на скриншоте:

Правила, указанные для конкретного бота, действуют только на него. Комбинация agent и disallow для «Яндекса» не сработает для Google. Потребуется создать отдельный блок.
Disallow и Allow: как правильно запрещать и разрешать
Для запрета применяется директива Disallow. Она показывает, что робот не должен индексировать конкретную страницу, раздел или полностью весь сайт.
Правильный синтаксис выглядит так:
Disallow:
Чтобы закрыть от индексирования весь ресурс, используют такой формат:
Disallow:/
Когда нужно закрыть разделы с одинаковым началом URL, применяют конструкцию со знаком *:
Disallow:*/
Иногда нужно запретить адрес с точным окончанием. Тогда используют знак доллара $:
Disallow:/admin$
Для разрешения доступа к определенным разделам используется директива Allow. Здесь также указывается путь после двоеточия, применяются знаки * и $. Пример комбинации user agent allow:
Allow:*/.pdf
Иногда один и тот же раздел отмечен обеими директивами. В таком случае действует правило: более длинный прописанный путь имеет приоритет. В примере ниже приоритет получит Allow:
Disallow:*/wasa
Allow:*/catalog/wasa
На скриншоте показан пример группы директив с разными параметрами.
Разные краулеры имеют свои особенности. Googlebot при конфликте agent disallow allow отдаст предпочтение Disallow, а «Яндекс» учитывает длину пути.
%201.png)
%201.png)
%201.png)
%201.png)
%201.png)
Sitemap: указываем путь к карте сайта
Чтобы боты быстрее находили Sitemap, необходимо указать путь к нему. Синтаксис требует прописывать полный абсолютный URL. Если карт несколько — каждую следует перечислить отдельной строкой. Допускается указание пути к сжатым форматам.

Все поисковые системы учитывают эту директиву, поэтому ее указывают вне групп. При ошибке в адресе краулеры пропустят строку.
Crawl-delay: замедляем роботов
Инструкция контролирует скорость переобхода для снижения нагрузки на сервер. После двоеточия указывается время задержки в секундах.
Crawl-delay: 2
Поддержка зависит от системы. «Яндекс» учитывает Crawl-delay — максимальное значение составляет 2 секунды; более высокие задаются через «Яндекс Вебмастер». Google полностью игнорирует команду, предлагая управлять скоростью через Search Console. Bing напрямую учитывает таймауты от 1 до 30 секунд.
Clean-param: инструкция для «Яндекса» по работе с динамическими URL
Команда упрощает обработку динамических адресов, предотвращая появление дублей. Если к контенту добавляется динамическая часть, директива запрещает переход по таким ссылкам.
Примеры использования для интернет-магазина:
Clean-param: lot&order&filter /catalog/
Можно не учитывать при сканировании адреса, появляющиеся при индивидуальных сессиях:
Clean-param: session_id&cdd /
Если трафик идет через рекламные системы, можно закрыть от индексации адреса с UTM-метками:
Clean-param: utm_source&utm_medium&utm_campaign&utm_content&utm_term /catalog/
Длина значения не должна превышать 500 символов — при необходимости создают несколько строк. Google игнорирует Clean-param, полагаясь на тег canonical.
Host: устаревшая директива
Ранее директива Host указывала на главное зеркало для «Яндекса». Google ее никогда не поддерживал.
С 2018 года «Яндекс» перестал её использовать, определяя зеркало автоматически. Для правильной склейки применяется 301-редирект или атрибут rel="canonical". Оставлять Host в файле нет смысла.
Специальные символы: *, $ и #
Звездочка (*) показывает, что в URL может быть любое количество символов. Робот будет игнорировать все адреса, попадающие под маску:
Disallow:*/catalog/sort-tomat/
Символ $ фиксирует конец строки. Пример запрета индексации файлов .docs:
Disallow:$.docs
Для комментариев существует оператор #. Строки после него игнорируются:
#Директивы для «Яндекс»
User-agent:YandexBot
Сравнение поддержки директив по поисковым системам
Директивы поддерживаются по-разному в зависимости от поисковой системы. Сводная таблица поможет избежать типичных ошибок при настройке правил для конкретного робота:
Директива |
Яндекс |
Bing |
|
Allow |
Да |
Да |
Да |
Disallow |
Да |
Да |
Да |
* (маска) |
Да |
Да |
Да |
$ (конец строки) |
Да |
Да |
Да |
Crawl-delay |
Нет |
Да (макс. 2 сек.) |
Да (1–30 сек.) |
Host |
Нет |
Устарела с 2018 г. |
Нет |
Clean-param |
Нет |
Да |
Нет |
Sitemap |
Да |
Да |
Да |
ТОП-15 ошибок в robots.txt, которые убивают трафик
Некоторые недочеты при настройке способны полностью остановить SEO-продвижение.
Неверное расположение файла
Документ обязан находиться строго в корневом каталоге. Домен и название файла должна разделять одна косая черта (https://example.com/robots.txt). Для переноса потребуется доступ к серверу.
Неправильное использование * и $
Спецсимволы способны случайно заблокировать полезный контент. Ошибка решается точечной корректировкой масок.
Блокировка CSS и JS файлов
Google требует доступ к CSS и JavaScript для корректного рендеринга страниц. Если сайт странно выглядит в кэше, необходимо проверить доступность скриптов и стилей, добавив исключения Allow.
Случайная блокировка всего сайта (Disallow: /)
Поисковая система получает прямой запрет на обход. Исправляется удалением строки.
Отсутствие пути к Sitemap
Файл sitemap.xml передает информацию о структуре. Добавление ссылки в robots.txt ускоряет обнаружение новых страниц.
Попытка использовать noindex в файле robots.txt
Robots.txt управляет сканированием, а не индексацией. Метатег noindex внутри текстового документа не работает. Правило прописывается в HTML-коде страниц.
Неправильный синтаксис (несколько каталогов в одном Disallow)
Каждая директива обязана располагаться на новой строке. Иначе парсинг ломается.
Использование кириллицы в путях без корректного кодирования
Для кириллических доменов применяется Punycode. Для путей — percent-encoding. Документ сохраняется в UTF-8 без BOM, иначе невидимый маркер сломает чтение первой строки.
Конфликт директив Allow и Disallow
При полном совпадении путей Google отдаст приоритет запрету.
Путаница с регистрами (case-sensitivity)
Пути чувствительны к регистру. /Catalog/ и /catalog/ — разные адреса для краулера.
Открытые для индексации служебные разделы
Админки, результаты внутреннего поиска и тестовые поддомены обязаны быть закрыты от обхода.
Неверно указанная директива Host
Директива устарела. Используется 301-редирект.
Чрезмерно высокий Crawl-delay
Слишком большое значение останавливает индексирование. Рекомендуемый максимум для Яндекса — 2 секунды.
Использование заглавных букв в имени файла (ROBOTS.TXT)
Системы ищут файл исключительно в нижнем регистре.
Некорректная структура группы правил
Создание нескольких блоков User-agent для одного бота — грубая ошибка. Все запреты объединяются в одну секцию.
Также в топ ошибок входит закрытие от сканирование раздела вместо страницы. Часто забывают добавить в конце символ $.
В остальном, больше недочеты. Оптимизаторы иногда забывают про регистры, про смысл файла (сканирование, а не индексация), добавить все файлы sitemap.

Правильный и неправильный синтаксис
Разобрать ошибку на примере проще, чем читать о ней в тексте. Ниже — семь типичных случаев с пояснениями.
Неправильно |
Правильно |
Суть ошибки |
|
|
Каждая директива — на отдельной строке |
|
|
Кириллица в пути недопустима; используйте Punycode или percent-encoding |
|
|
Пути чувствительны к регистру |
|
|
Sitemap требует полного абсолютного URL с протоколом |
|
|
Без $ или / маска захватывает все URL, начинающиеся с /admin |
|
|
Несколько блоков для одного User-agent — ошибка; объединяйте в одну группу |
Файл сохранён в UTF-8 с BOM |
Файл сохранён в UTF-8 без BOM, Content-Type: text/plain |
BOM-маркер ломает парсинг директив с первой строки |
Шаблоны robots.txt для разных типов сайтов
Универсального файла robots.txt не существует. Структура сайта определяет, что именно нужно закрыть или разрешить. Ниже — базовые шаблоны для четырёх наиболее распространённых типов проектов.
Тип сайта |
Что блокировать |
Что разрешать |
Особые нюансы |
Интернет-магазин |
Страницы сортировки, фильтров, корзины, личного кабинета, результатов внутреннего поиска |
Карточки товаров, категории, CSS/JS/шрифты, sitemap |
Для Яндекса добавляйте Clean-param для UTM, session_id и фасетных параметров (sort, filter, order); не блокируйте целые разделы без символа $ |
Блог / СМИ |
Страницы тегов, архивы по дате, страницы авторов (если дублируют контент), служебные страницы CMS |
Статьи, категории, изображения, sitemap |
Не закрывайте /wp-includes/ и /wp-content/themes/ полностью — CSS и JS нужны для рендеринга |
SaaS / лендинг |
Административная панель, страницы авторизации, API-эндпоинты, тестовые окружения |
Все публичные посадочные страницы, блог, sitemap |
Проверьте, что staging-окружение полностью закрыто от индексации; для продуктивной среды оставьте минимум ограничений |
Мультидомен / CDN |
Дублирующие поддомены, технические субдомены (api., static.) |
Основной домен, публичный контент, sitemap |
После каждого обновления robots.txt сбрасывайте кэш на уровне CDN; убедитесь, что файл на каждом поддомене актуален |
Как проверить robots.txt на ошибки
Для аудита применяются консоли для вебмастеров и серверные утилиты.
%201.png)
HTTP-заголовки: первое, что нужно проверить
Для быстрой технической диагностики в консоли используют команду: curl -I https://example.com/robots.txt. В ответе должны присутствовать:
- Статус 200 OK — файл найден.
- Content-Type: text/plain — передаётся как текст.
- Без редиректов (301, 302) — переадресация мешает краулерам.
Статусы 404 или 410 означают, что роботы сканируют сайт без ограничений. Ошибки 5xx заставляют поисковики временно приостановить обход.
Проверка в Google Search Console
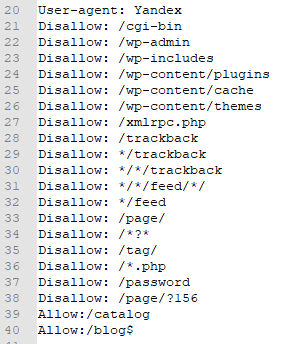
В панели Search Console необходимо перейти в «Настройки», найти строку robots.txt и нажать «Открыть отчет».
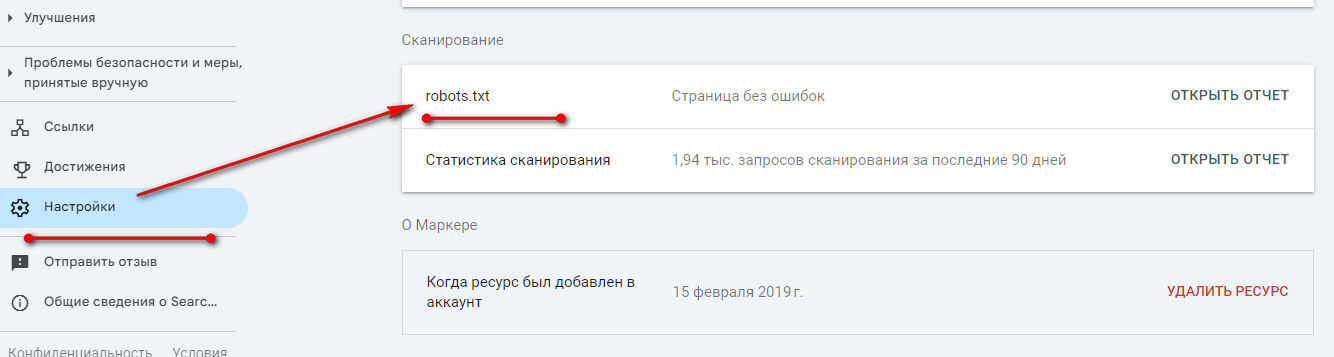
Система покажет количество проблем и предупреждений. Ошибки для Google могут оказаться валидными правилами для Яндекса (например, Clean-param).
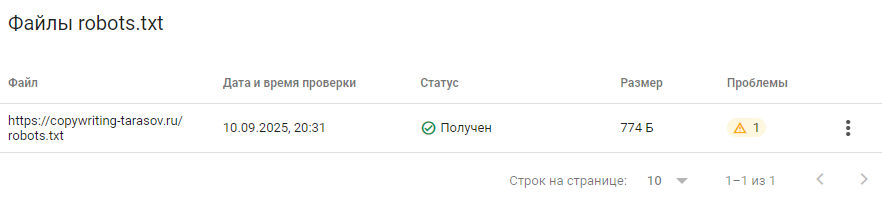
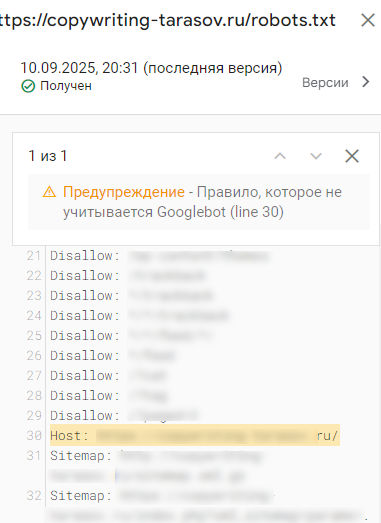
В открывшемся окне отображаются параметры, нарушающие логику Google. В примере ниже это директива Host:
Проверка в «Яндекс Вебмастере»
Инструмент находится в меню «Инструменты» → «Анализ robots.txt».
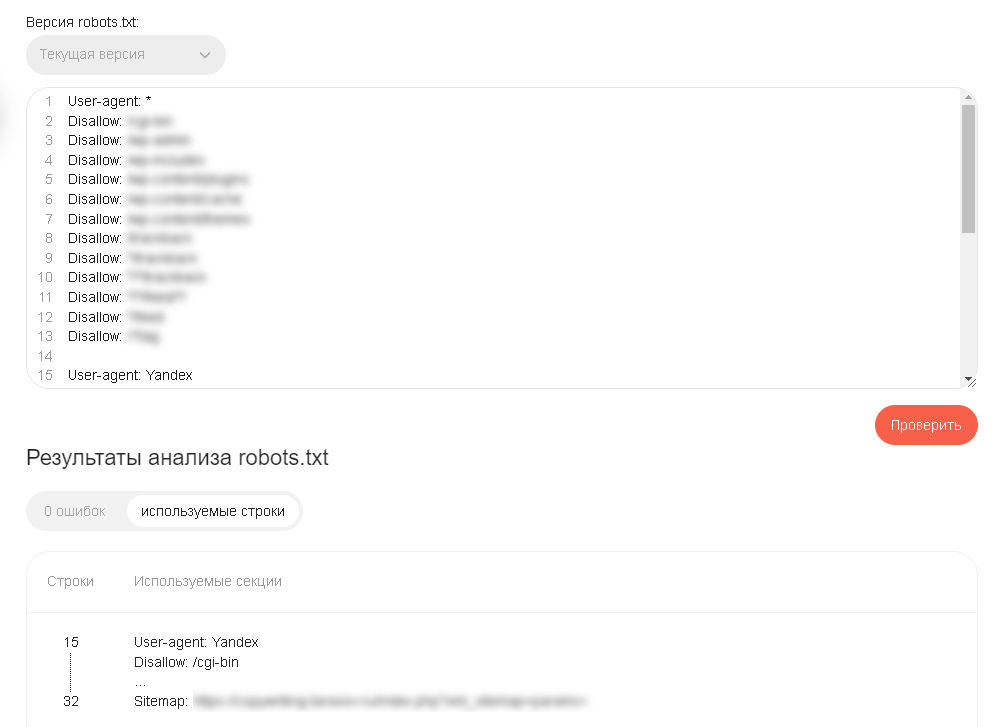
Сервис позволяет проверить альтернативный код до публикации на сервере и протестировать доступность конкретных URL.
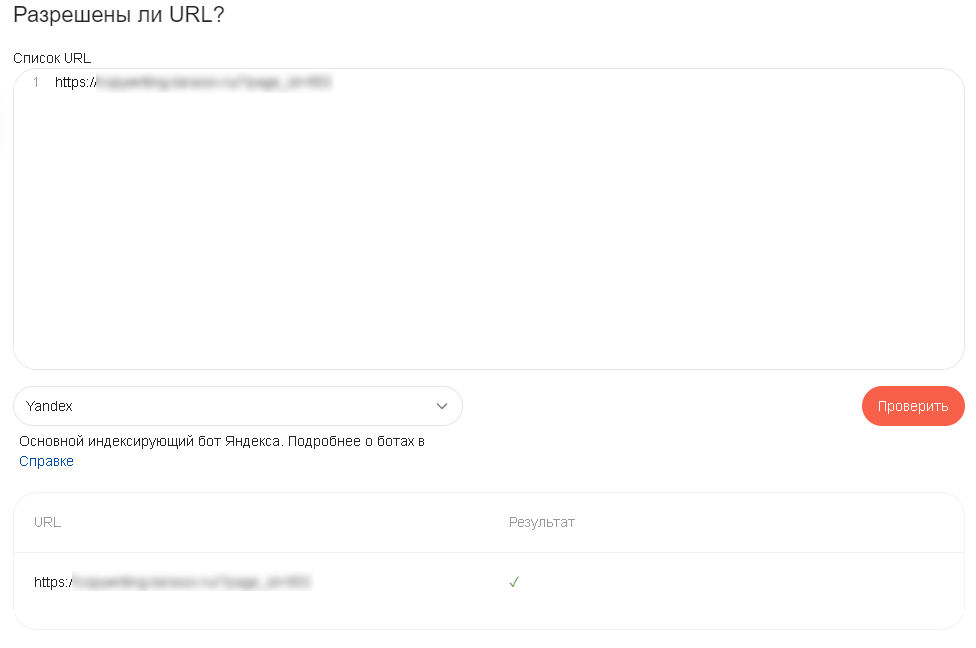
Для проверки конкретного URL на разрешение к индексации достаточно вставить список адресов в нижнее поле и нажать «Проверить».
Проверка через SEO-краулеры и логи сервера
Программы вроде Screaming Frog формируют отчёт «Blocked by robots.txt» — список страниц, не попадающих в индекс из-за ограничений. Это удобно для глубокого аудита.
После обновления конфигурации стоит проверить логи сервера. Наличие ошибок 404, 403 или 410 при запросах от Googlebot или YandexBot сигнализирует о проблемах с доступом. При использовании CDN обязательно выполняется сброс кэша (purge), чтобы боты получили новую версию.
Восстановление после ошибок и профилактика
Если ошибка повлияла на трафик, необходимо скорректировать правила и подтвердить изменения через краулеры. После проверки отправляется запрос на переобход в Search Console и Вебмастере.
Точных сроков восстановления нет. Остается быстро выполнить технические шаги и ждать обновления кэша поисковиков.
Лучшее решение — профилактика. Редактирование требует аккуратности. Изменения стоит предварительно тестировать в песочнице.
Песочница — специально выделенная (изолированная) среда для безопасного исполнения компьютерных программ.
При падении позиций важно без паники проанализировать проблему, внести правки и отправить sitemap на переобход.
Важно: Robots.txt управляет сканированием, но не защищает контент. Закрытая от индексации страница остаётся доступной по прямой ссылке для любого пользователя. Для реальной защиты закрытых разделов используйте авторизацию или ограничение доступа по IP.
FAQ по robots.txt
Что будет, если файла нет?
Сайт продолжит индексироваться, но хаотично. Технические дубли попадут в выдачу, расходуя лимиты обхода.
Как robots.txt влияет на краулинговый бюджет?
Закрытие мусорных страниц экономит лимиты, перераспределяя внимание ботов на полезный контент.
Что будет, если закрыть сайт от индексации?
Ресурс постепенно выпадет из поиска. На практике известны кейсы, когда случайный запрет приводил к полной потере органического трафика за пару недель.
Заключение
Регулярный аудит файла обязателен при любых технических доработках. Своевременное снятие запретов со страниц после редизайна сохранит позиции. Документ требует постоянной поддержки в актуальном состоянии.
Коротко о главном
- Документ управляет краулинговым бюджетом, но не защищает информацию от пользователей.
- Сервер обязан отдавать статус 200 OK и Content-Type: text/plain. Лимит размера: 32 КБ для «Яндекса», 500 КБ для Google.
- Поддержка команд различается: Crawl-delay игнорируется Google, Host устарела.
- Проверка выполняется через Search Console, Вебмастер, логи сервера и команду curl.
- После обновления обязательно сбрасывается кэш CDN.
- Синтаксис чувствителен к регистру, кодировке (UTF-8 без BOM) и спецсимволам.



.png)
.png)



Комментарии (8)
Оставить комментарий