

Представьте библиотеку, где каждая книга — это отдельный набор информации. В этой библиотеке могут быть книги по разным темам: истории, науке, искусстве и т.д. Так же и в датасете: он может содержать различные типы данных, такие как числа, текст или изображения, сгруппированные по определенным категориям.
- Что такое датасет, из чего он состоит
- Почему датасеты важны
- Виды датасетов
- Как создать датасет
- Где найти датасеты
- Использование датасетов в машинном обучении
- Оценка качества модели
- Примеры применения датасетов
- Дополнительные рекомендации
- Коротко о главном
Что такое датасет, из чего он состоит
Датасет (dataset) — это обработанный и структурированный массив данных, который используется для построения гипотез, выводов или обучения нейросетей.
Рассмотрим основные компоненты наборов данных, различные типы, а также популярные форматы, в которых они могут храниться.
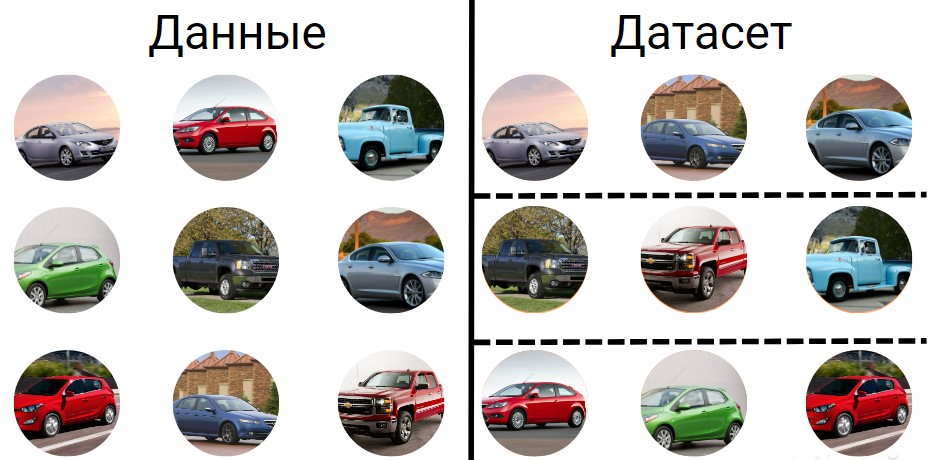
Структура датасета
Dataset обычно представляется в виде таблицы, где строки соответствуют записям (объектам), а столбцы — признакам (характеристикам) этих объектов.
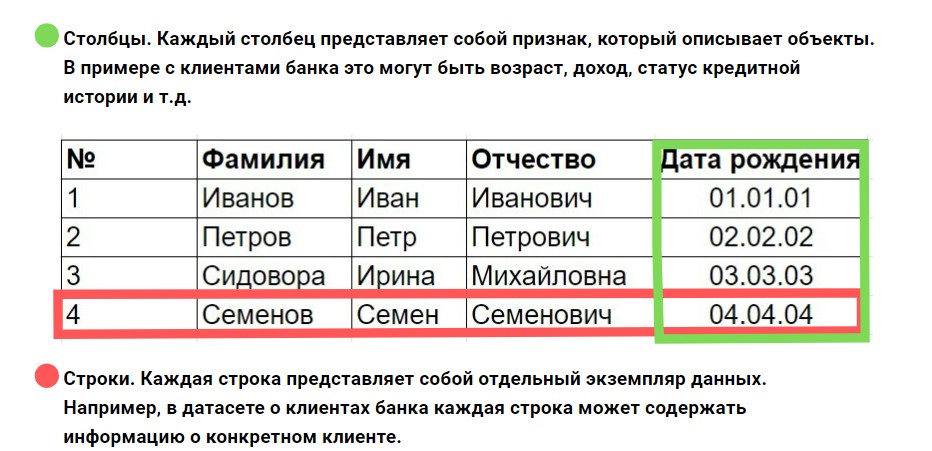
Сами признаки представляют собой характеристики, которые используются для описания объектов. Они могут быть числовыми, категориальными или текстовыми. Кроме того, в формировании наборов данных могут участвовать метки — целевая переменная, которую мы пытаемся предсказать или классифицировать.
Например, в задаче классификации клиентов по вероятности дефолта (неоплата своевременно кредита или процентов по нему) меткой может быть бинарная переменная (0 или 1), указывающая на то, должник клиент или нет.

Типы данных в датасетах
Данные в сетах могут быть разных типов, и правильное понимание этих типов критично для их анализа и обработки.
Числовые данные представляют собой количественные значения:
- Целочисленные. Например, количество товаров на складе.
- Действительные. Например, цена товара или температура.
Категориальные данные представляют собой качественные характеристики и делятся на:
- Номинальные. Например, цвет автомобиля (красный, синий, зеленый).
- Порядковые. Например, уровень образования (начальное, среднее, высшее), где есть порядок.
Текстовые данные содержат неструктурированную информацию и могут включать отзывы клиентов, статьи и т.д. Обработка текстовых данных часто требует применения методов обработки естественного языка (NLP).
Временные данные представляют собой временные метки и используются для анализа временных рядов. Например, дата и время покупки товара. Существуют также другие типы данных: булевы (true/false) или сложные структуры (например, списки или словари).
Форматы датасетов
Выбор формата хранения данных зависит от целей анализа и используемых инструментов. Рассмотрим несколько популярных форматов:
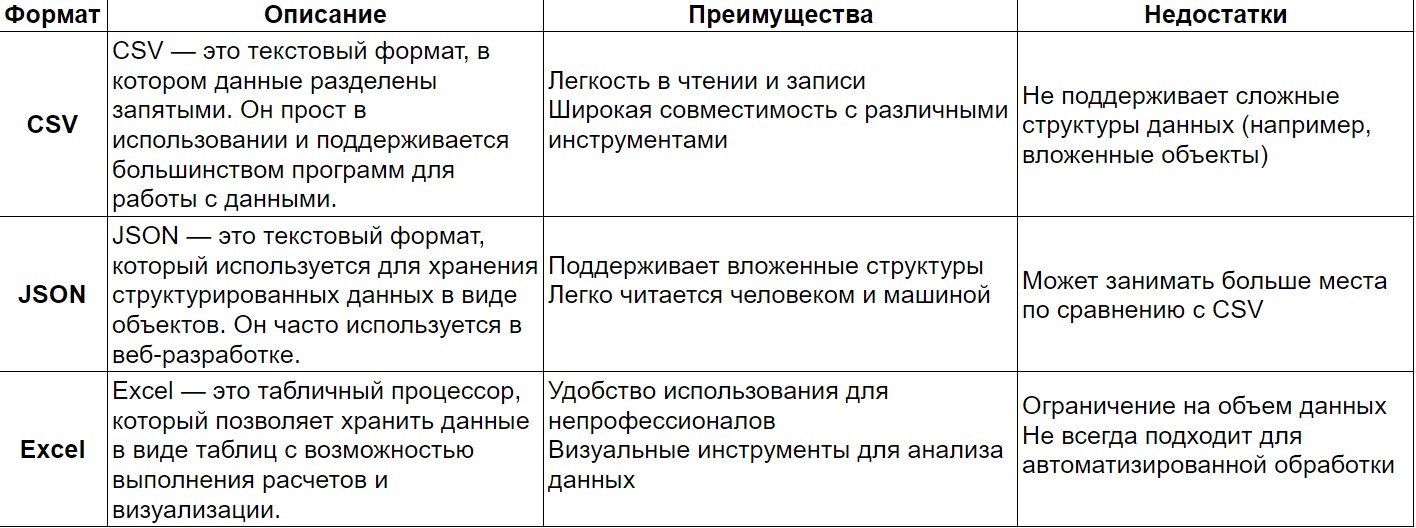
Существуют и другие форматы хранения данных, такие как Parquet (оптимизированный для хранения больших объемов данных), HDF5 (для научных вычислений) и SQL базы данных (для реляционных данных).
Почему датасеты важны
Датасеты служат основой для машинного обучения, которое включает в себя использование данных для настройки параметров модели. Например, в задачах классификации алгоритм изучает, какие признаки (факторы) делают данные похожими или различными, чтобы корректно классифицировать новые объекты. Без качественного набора данных модель не сможет эффективно обучаться и будет давать неточные результаты. Они играют важную роль не только в машинном обучении, но и в анализе данных. Организации используют статистические методы для изучения своих данных и выявления скрытых закономерностей.
Например, компании могут анализировать данные о продажах, чтобы выявить тренды потребительского поведения и оптимизировать свои маркетинговые стратегии. Dataset позволяют им отслеживать эффективность рекламных кампаний, определять целевую аудиторию и прогнозировать спрос на продукты.

Виды датасетов
Dataset можно классифицировать по нескольким критериям: области применения, размеру и доступности.
По области применения
Для компьютерного зрения
Компьютерное зрение — это область искусственного интеллекта, которая фокусируется на том, чтобы дать компьютерам возможность «видеть» и интерпретировать визуальную информацию. Включает в себя:
- Изображения. CIFAR-10 содержит 60 000 изображений в 10 классах.
- Видеоданные. UCF101, содержат видео для задач распознавания действий.
- Сегментация. COCO (Common Objects in Context) предоставляют аннотированные изображения для задач сегментации объектов.
Для обработки естественного языка (NLP)
Обработка естественного языка включает в себя анализ и генерацию текстовой информации. Наборы для NLP могут включать:
- Текстовые корпуса. IMDB содержит рецензии на фильмы для анализа тональности.
- Диалоги. Cornell Movie Dialogs Corpus используются для обучения чат-ботов.
- Перевод. WMT (Workshop on Machine Translation), содержат параллельные тексты для задач машинного перевода.

Для рекомендательных систем
Рекомендательные системы используют данные о пользователях и их предпочтениях для предоставления персонализированных рекомендаций. Примеры:
- Пользовательские рейтинги. MovieLens содержит рейтинги фильмов от пользователей.
- История покупок. Amazon Product Data предоставляет информацию о покупках пользователей для анализа предпочтений.
Для распознавания речи
Распознавание речи — это область, которая позволяет компьютерам интерпретировать и преобразовывать устную речь в текст. Для обучения моделей в этой области используются:
- LibriSpeech. Один из наиболее популярных наборов для распознавания речи, содержащий аудиозаписи книг, прочитанных добровольцами. Он включает более 1 000 часов записей и аннотации текста.
- Common Voice. Проект Mozilla, который собирает голосовые данные от пользователей по всему миру. Он содержит записи на различных языках и акцентах, что делает его полезным для разработки многоязычных систем.
Для анализа текстов
Анализ текстов охватывает широкий спектр задач, включая классификацию, анализ тональности и извлечение информации. Для этих целей используются:
- IMDB. Сет данных рецензий на фильмы, который используется для анализа тональности (положительная или отрицательная) и классификации текстов.
- 20 Newsgroups. Содержит 20 различных групп новостей и используется для задач классификации и кластеризации текстов.
- CoNLL-2003. Набор для задачи распознавания именованных сущностей (NER). Он содержит аннотированные тексты с выделением имен собственных, таких как имена людей, организации и места.
- SQuAD (Stanford Question Answering Dataset). Dataset, предназначенный для задач вопросно-ответного взаимодействия, содержащий вопросы и соответствующие ответы из статей Википедии.
- WMT (Workshop on Machine Translation). Серия ежегодных конкурсов по машинному переводу, предоставляющая параллельные тексты на разных языках.
Для анализа изображений
Анализ изображений включает в себя задачи классификации, сегментации и обнаружения объектов. В этой области также существует множество специализированных наборов:
- ImageNet. Один из самых больших и известных, содержащий более 14 миллионов изображений, аннотированных по более чем 20 000 категориям. Широко используется для обучения моделей глубокого обучения.
- CIFAR-10/100. Наборы данных с 60 000 цветных изображений в 10 или 100 классах соответственно. Часто используются для тестирования алгоритмов компьютерного зрения.
- COCO (Common Objects in Context). Содержит изображения с аннотациями для задач сегментации объектов и обнаружения объектов в контексте.
- PASCAL VOC. Содержит изображения с аннотациями для задач классификации и сегментации объектов. Широко используется в соревнованиях по компьютерному зрению.
- YOLO (You Only Look Once). Создан для обучения моделей обнаружения объектов в реальном времени. Обеспечивает аннотации для различных объектов на изображениях.
- Open Images. Один из крупнейших наборов с аннотированными изображениями, содержащий миллионы изображений с разметкой объектов.
.jpg)
По размеру
Малые обычно содержат менее 1 000 записей и часто используются для обучения и тестирования простых моделей. Примеры:
- Iris Dataset. Содержит 150 записей о цветах ириса.
- Wine Quality Dataset. Содержит 1 599 записей о качестве вина.
Средние содержат от 1 000 до нескольких десятков тысяч записей. Они подходят для более сложных задач и моделей:
- Titanic Dataset. Содержит информацию о пассажирах Титаника и используется для предсказания выживаемости.
- Adult Income Dataset. Содержит данные о доходах людей и используется для предсказания уровня дохода.
Большие содержат миллионы записей и используются для сложных моделей и глубокого обучения:
- ImageNet. Содержит более 14 миллионов изображений, аннотированных по категориям.
- Common Crawl. Огромный сет веб-страниц, используемый для различных задач NLP и анализа данных.
По доступности
Публичные доступны всем без ограничений и часто используются в научных исследованиях и разработках:
- Kaggle Datasets.
- UCI Machine Learning Repository.
Частные принадлежат организациям или компаниям и могут быть доступны только определённым пользователям или по запросу:
- Корпоративные данные. Например, данные о клиентах или транзакциях внутри компании.
- Научные исследования. Часто данные собираются в рамках исследований и доступны только авторам или участникам проекта.
Открытые предоставляются с минимальными ограничениями на использование и часто имеют открытые лицензии:
- Open Data Portal. Платформы вроде Data.gov предлагают открытые данные от правительств и организаций.
- World Bank Open Data. Данные о мировом развитии, экономике и социальных показателях.
Как создать датасет
Создание качественного dataset — это важный этап в разработке моделей машинного обучения. Хорошо подготовленный набор данных может значительно повысить точность и надежность моделей. Разберем основные этапы.
Этап 1. Сбор данных
Это первый и самый критический этап в создании Dataset.
Существует множество источников, откуда можно получить данные, приведем основные из них:
- Веб-скрапинг. С помощью библиотек, таких как Beautiful Soup или Scrapy, можно собирать данные с веб-сайтов. Это особенно полезно для получения текстовой информации, изображений и других медиафайлов.
- API. Многие платформы (например, X, Reddit) предоставляют API для доступа к данным. Использование API позволяет получать структурированные данные без необходимости их парсинга.
- Открытые базы. Существуют множество открытых баз данных, доступных для скачивания (например, Kaggle, UCI Machine Learning Repository). Эти базы данных часто уже аннотированы и очищены.
- Корпоративные базы. При работе в компании, можно получить доступ к внутренним базам, где уже содержатся необходимые данные.
Этап 2. Очистка
После сбора данных необходимо провести их очистку. Приведем основные шаги по очистке данных:
- Обработка пропущенных значений. Если пропущенные значения составляют небольшой процент от общего объема данных, их можно просто удалить. Для более значительных пропусков можно использовать методы импутации (например, заполнение средним значением, медианой или использованием более сложных алгоритмов).
- Удаление дубликатов. Это можно сделать с помощью простых функций в библиотеках Pandas (например, drop_duplicates()).
- Нормализация данных. Нормализация помогает привести данные к единому масштабу. Это особенно важно для алгоритмов, чувствительных к масштабу (например, KNN или SVM).
Подготовка
На этом этапе необходимо подготовить данные для обучения модели:
- Провести сегментацию на обучающую и тестовую выборки. Данные разделяют на три части: обучающую, валидационную и тестовую выборки. Это позволяет избежать переобучения и оценить качество модели на новых данных.
- Преобразовать данные. Преобразование текстовых категорий в числовые значения (например, с помощью One-Hot Encoding) и создание новых признаков на основе существующих: например, извлечение даты из временной метки.
Разметка данных
Разметка данных — это процесс аннотирования ваших данных для обучения модели. Разметка зависит от типа задачи:
- Классификация. Для задач классификации необходимо аннотировать данные метками классов. Например, если вы работаете с изображениями животных, каждое изображение должно быть помечено как "кот", "собака" и т.д.
- Регрессия. Для задач регрессии вам нужно аннотировать данные числовыми значениями. Например, если вы предсказываете цены на жилье, каждая запись должна содержать цену.
- Сегментация. Сегментация изображений требует более сложной разметки, где каждое пиксельное значение должно быть помечено соответствующим классом (например, фон, объект). Это часто делается с помощью инструментов разметки изображений, таких как LabelMe или VGG Image Annotator.
От сбора и очистки данных до их подготовки и разметки — каждый шаг имеет значение для успешного обучения модели машинного обучения.
Где найти датасеты
Рассмотрим три самых популярных репозитория: Kaggle, Google Dataset Search и UCI Machine Learning Repository.
Kaggle
Сайт: https://www.kaggle.com/
Kaggle — это одна из самых популярных платформ для соревнований по машинному обучению и анализу данных. Она предлагает не только возможность участвовать в конкурсах, но и обширную библиотеку открытых наборов, которые пользователи могут использовать для своих проектов.
Преимущества:
- Разнообразие. Kaggle предлагает много наборов по различным темам — от здравоохранения до финансов и экологии.
- Сообщество. Платформа имеет активное сообщество, где пользователи могут делиться решениями, обсуждать подходы и получать советы.
- Инструменты. Kaggle предоставляет встроенные инструменты для анализа данных, включая Jupyter Notebooks.
Недостатки:
- Качество данных. Поскольку многие сеты загружаются пользователями, качество может варьироваться.
- Размеры файлов. Некоторые наборы могут быть очень большими, что требует значительных ресурсов для обработки.
Google Dataset Search
Сайт: https://datasetsearch.research.google.com/
Google Dataset Search — это инструмент от Google, который позволяет искать наборы данных по всему интернету. Он индексирует данные из различных источников и делает их доступными для пользователей.
Преимущества:
- Широкий охват. Google Dataset Search охватывает множество источников, включая правительственные сайты, научные публикации и другие репозитории.
- Удобство поиска. Пользователи могут легко находить наборы по ключевым словам и фильтровать результаты по различным критериям.
Недостатки:
- Отсутствие контроля качества. Поскольку Google просто индексирует данные, качество и актуальность могут варьироваться.
- Нет встроенных инструментов. В отличие от Kaggle, Google Dataset Search не предлагает инструментов для анализа данных.
UCI Machine Learning Repository
Сайт: https://archive.ics.uci.edu/datasets
UCI Machine Learning Repository — это один из старейших ресурсов для поиска датасетов в области машинного обучения. Он был создан в 1987 году и с тех пор стал стандартом для многих исследователей.
Преимущества:
- Качество данных. Наборы на UCI часто проходят проверку на качество и соответствие.
- Структурированность. Данные организованы по категориям, что облегчает поиск нужной информации.
- Обширная документация. Каждый сет сопровождается описанием, что помогает понять его структуру и контекст.
Недостатки:
- Ограниченное количество новых данных. Платформа может не предлагать самые современные или специфические наборы данных.
- Пользовательский интерфейс. Некоторые пользователи могут считать интерфейс устаревшим по сравнению с современными платформами.

Использование датасетов в машинном обучении
Использование датасетов в машинном обучении является основой для разработки эффективных моделей, способных решать сложные задачи в различных областях. Расскажем про процесс обучения модели, методы оценки ее качества и примеры применения Dataset в различных областях.
Обучение
На этапе обучения модель обучается на тренировочном наборе данных. Этот набор состоит из входных данных и соответствующих им выходных значений (меток). Модель использует алгоритмы машинного обучения для нахождения паттернов и зависимостей в данных. Важно, чтобы тренировочный набор был достаточно большим и разнообразным и модель могла обобщать свои знания на новые данные.
Валидация
Валидация помогает избежать переобучения (overfitting), когда модель слишком хорошо запоминает тренировочные данные и теряет способность обобщать. На этом этапе модель тестируется на валидационном наборе данных, который не использовался во время обучения. Это позволяет настраивать гиперпараметры модели и выбирать лучший вариант алгоритма.
Тестирование
Тестирование проводится на отдельном тестовом наборе данных, который также не использовался в процессе обучения или валидации. Этот этап позволяет оценить, как хорошо модель будет работать на новых, невидимых данных. Результаты тестирования помогают понять реальную производительность модели и ее готовность к применению в реальных условиях.
Оценка качества модели
Оценка качества модели — это важный шаг, который позволяет определить, насколько хорошо она справляется с поставленной задачей. Существует несколько метрик, которые используются для оценки качества моделей:
Точность (Accuracy)
Точность — это доля правильно предсказанных значений от общего числа предсказаний. Она рассчитывается по формуле:

Полнота (Recall)
Полнота показывает, насколько хорошо модель находит положительные примеры. Она рассчитывается по формуле:

Полнота важна в задачах, где необходимо минимизировать количество пропущенных положительных случаев.
F1-мера
F1-мера является гармоническим средним между точностью и полнотой. Она используется, когда необходимо сбалансировать оба показателя:

Примеры применения датасетов
Датасеты находят применение в самых различных областях. Рассмотрим несколько примеров использования машинного обучения в реальных сценариях.
Медицина
В медицине машинное обучение используется для диагностики заболеваний на основе медицинских изображений: например, рентгеновских снимков или МРТ.
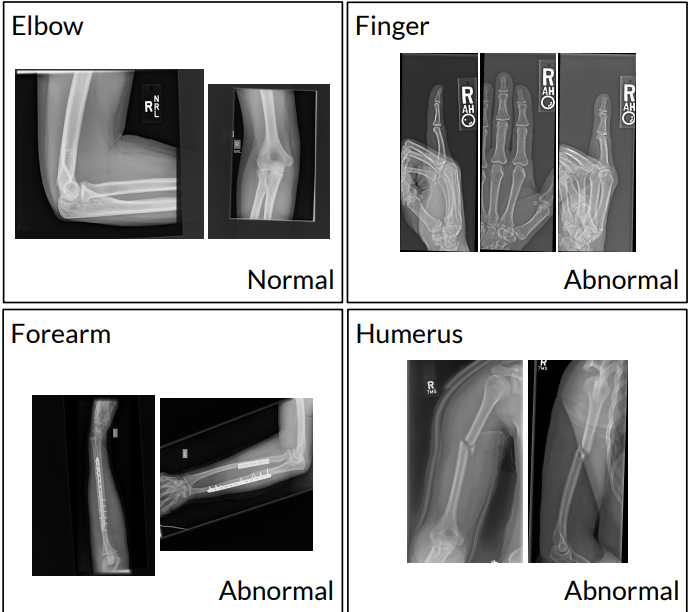
Датасеты с изображениями пациентов помогают моделям обучаться различать здоровые и больные ткани. Например, алгоритмы могут идентифицировать рак на ранних стадиях, что значительно увеличивает шансы на успешное лечение.
Финансы
В финансовой сфере машинное обучение применяется для анализа кредитоспособности клиентов и обнаружения мошенничества. Датасеты о транзакциях клиентов позволяют моделям выявлять аномалии в поведении, которые могут свидетельствовать о мошеннических действиях. Такие системы помогают снизить риски и повысить безопасность финансовых операций.
Маркетинг
В маркетинге машинное обучение используется для сегментации клиентов и предсказания их поведения. Датасеты о покупках и взаимодействиях пользователей с продуктами позволяют компаниям создавать персонализированные предложения и улучшать клиентский опыт. Например, алгоритмы могут рекомендовать товары на основе предыдущих покупок, что повышает вероятность успешной продажи.
Дополнительные рекомендации
В поисках необходимых dataset обратите внимание на Google Dataset Search — это ключевой ресурс для их нахождения. Большое количество информации также собрано на платформе Kaggle, которая специализируется на проведении конкурсов в области машинного обучения.
Для анализа и создания базы данных важно собрать статистику по датасету. Это поможет вам лучше понять его структуру, выявить возможные дисбалансы между классами и оценить объем данных, полученных из различных источников для каждого класса.
Разделите исходный набор данных на две части: обучающую и контрольную. Обычно для обучения выбирают 70–80 % изображений, а оставшиеся 20–30 % используют для проверки. Обучающая часть служит для того, чтобы нейросеть научилась распознавать объекты, а контрольная — для оценки точности модели.
Чтобы не допустить смешивания данных, рекомендуется применять специализированные скрипты и библиотеки, которые автоматически исключают дубликаты. Также можно настроить порог для удаления, например, выставляя параметр на удаление абсолютно идентичных изображений или тех, которые похожи на 90 %.
Уменьшите объем данных. При подготовке базы данных для конкретной задачи следует стремиться к ее минимизации. После определения целевого атрибута (значения, которые вы хотите предсказать), можно предположить, какие данные являются ключевыми для модели и какие просто добавляют к базе данных лишние размерности и сложность, не влияя на качество прогнозирования.

Коротко о главном
- Датасеты являются основой машинного обучения, они помогают настраивать параметры моделей. Без качественных данных модели обучаются неэффективно и дают неточные результаты.
- Датасет — это структурированный массив данных, используемый для обучения нейросетей и проведения анализа.
- Он состоит из строк (объектов) и столбцов (признаков). Типы данных включают числовые, категориальные и текстовые.
- Популярные форматы хранения данных включают CSV, JSON и Excel. Выбор формата зависит от целей анализа и используемых инструментов.
- По области применения они бывают для: компьютерного зрения, обработки естественного языка (NLP), рекомендательных систем, распознавания речи, анализа текстов и изображений.
- Основные этапы создания датасета включают сбор, очистку, подготовку и разметку данных.
- Три популярных источника наборов данных: Kaggle, Google Dataset Search и UCI Machine Learning Repository.
- Использование датасетов в машинном обучении включает обучение модели, валидацию и тестирование. Обучение происходит на тренировочном наборе данных, валидация предотвращает переобучение, а тестирование оценивает работу модели на новых данных.
- Оценка качества модели помогает определить, насколько хорошо она решает задачу. Метрики для оценки качества моделей включают точность, полноту и F1-меру.
- Dataset применяются в разных сферах, например, в медицине для диагностики заболеваний, в финансах для анализа кредитоспособности и обнаружения мошенничества, а также в маркетинге для сегментации клиентов и предсказания их поведения.

.png)

.png)
.png)
