

Когда-то я работал в веб-студии и получил задание проверить, почему один из сайтов никак не продвигается. Причину нашел: все дело было в одном файле, из-за которого все и началось.
Теперь я убежден, что каждому, кто имеет дело с сайтами, нужно знать…
- Что такое robots.txt
- Зачем он нужен?
- Синтаксис и директивы
- Как создать robots.txt
- Как запретить индексацию в robots.txt
- Сервисы проверки robots.txt
Что такое robots.txt
Robots.txt — это текстовый файл, содержащий в себе указания, как роботам поисковых систем нужно индексировать сайт.
Этот файл размещается в корневом каталоге сайта:
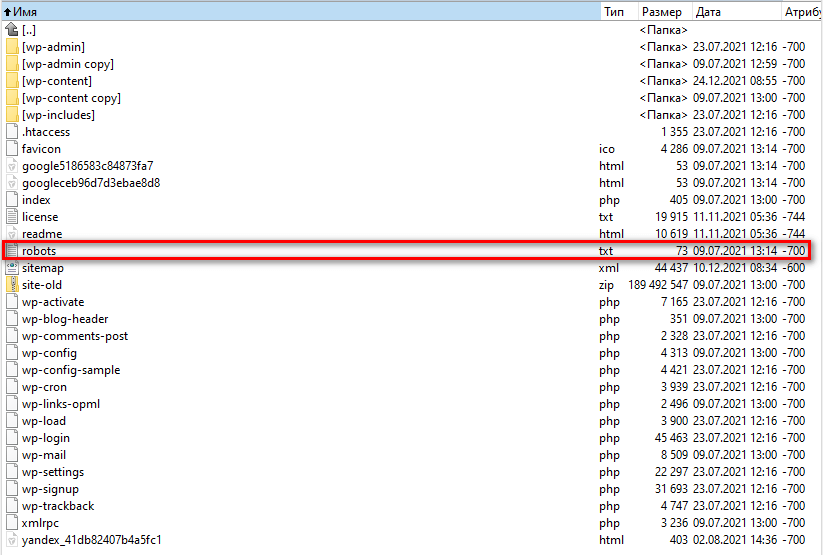
Структурно файл состоит из разделов, директивы которых либо закрывают, либо открывают доступ поисковым роботам к разным страницам и папкам сайта.
У каждой поисковой системы есть специфические требования к работе с файлом:
Безусловным плюсом файла является тот факт, что его всегда можно отредактировать: например, для скрытия из индекса новых служебных страниц, конфиденциальной информации, административной панели.
Для этого к нему нужно получить доступ по FTP, открыть в любом текстовом редакторе («Блокнот», Notepad++, Sublime) и внести правки. Далее файл надо сохранить и скопировать в корень своего сайта с заменой старой версии файла. И обязательно нужно будет проверить его, введя mysite/robots.txt, где mysite — название вашего сайта.
Будет не лишним прогнать файл через валидаторы: о них мы поговорим далее.

Зачем он нужен?
- формирование перечня страниц для индексации поисковыми системами;
- снижение серверной нагрузки в момент обхода сайта краулерами;
- прописывание главного зеркала сайта (с WWW или без WWW);
- прописывание пути к карте сайта (sitemap.xml);
- формирование директив, предписывающих специфические правила обхода страниц.
Бывает, что в файле корректно прописаны директивы, а поисковые роботы их не учитывают. Это говорит о том, что допущены синтаксические ошибки:
- Размер файла превысил максимально для него допустимый: 500 килобайт для «Яндекса» и 500 кибибайт для Google.
- Директивы прописаны в другой кодировке, отличной от UTF-8 (актуально для Google).
- Файл не является текстовым (обязательно проверяйте, чтобы расширение было TXT) и в его названии содержатся недопустимые символы.
- По каким-то причинам к файлу нельзя получить доступ на сервере.

Именно поэтому нужно периодически обращаться к корневому каталогу своего сайта и проверять доступ к robots.txt, а также валидность его содержимого.


Синтаксис и директивы
Синтаксис разделяют две части:
- обязательные директивы;
- необязательные директивы.
Чтобы краулеры поисковых систем корректно воспринимали эти директивы, их нужно размещать в строго определенном порядке. Первой директивой очередного раздела должна быть User Agent, затем запрет Disallow, затем разрешение Allow и затем Host, основное зеркало сайта.
Самое важное — не делать ошибок и внимательно следить за тем, как записаны директивы. Помните, в начале статьи я рассказывал про всего один символ, который свел насмарку всю работу по SEO? Это была директива “Disallow: /”, благодаря которой весь сайт был закрыт от индексации. Так часто делают программисты, когда закрывают тестовую версию сайта от попадания в выдачу поисковых систем.
Главное — как только сайт будет выложен на сервер, открыть для индексации его полностью или поставить запрет на некоторые страницы.
Если вы не хотите допустить подобного, нужно знать ряд правил работы с синтаксисом:
- Одна строка — одна директива.
- Любая директива записывается только с новой строки.
- Недопустимы пробелы в начале строк и между ними.
- Когда вы описываете параметр, его нельзя переносить на новую строку.
- Как в названии самого файла, так и в параметрах директив не должно быть строчных букв.
- Перед всеми папками нужно ставить прямой слэш (/): например /category.
- Все директивы описываются только латинскими символами.
- Допускается использовать в директивах Allow и Disallow только один параметр.
- Если Disallow не содержит в себе параметр, она считается эквивалентной Allow: /, что разрешает индексацию всех страниц сайта.
- Если Allow не содержит в себе параметр, онай считается эквивалентной Disallow: /, что запрещает индексацию всех страниц сайта.

Теперь рассмотрим основные директивы:
-
User-agent. Обязательная директива, которая прописывается в первой строке файла и инициирует обращение к роботам поисковых систем:
User-agent: *
# обращение ко всем поисковым системам
User-agent: Yandex
# обращение только к роботу «Яндекса»
User-agent: Googlebot
# обращение только к роботу Google
-
Disallow. Эта директива запрещает обход различных частей сайта:
User-agent: *
Disallow: /category
# всем роботам закрыта индексация раздела и всех страниц, в него входящих
-
Allow. Директива разрешает обход всех разделов сайта и страниц, в них входящих:
User-agent: *
Allow: /
# всем роботам поисковых систем разрешен обход всего сайта
-
Noindex. Директива обеспечивает запрет обход части контента определенной страницы. Отличается от директивы Disallow, потому записывается прямо в код страницы и имеет следующий вид:
<meta name=”robots” content=”noindex” />
-
Clean-param. Директива запрещает индексацию параметров в адресе страницы. Существенна только для краулера «Яндекса». Благодаря ей можно закрыть от индексации UTM и не допустить дублирования страниц:
Clean-param: utm # директива будет применяться к параметрам на страницах по любому адресу
-
Crawl-Delay. Директива задает минимальный временной период между обходом страниц роботом:
User-agent: Googlebot
Disallow: /admin
Crawl-delay: 4
# после индексации страницы робот Google начнет индексировать следующую не раньше. чем через 4 секунды.
-
Host. Директива, указывающее главное зеркало сайта:
Host: mysite.com
# указали без WWW
-
Sitemap. Директива пути к карте сайта:
Sitemap: yoursite.com/sitemap.xml

Как создать robots.txt
Как видите, особой сложности в формировании файла нет, и поэтому сначала его можно попробовать сделать…
Вручную
Создаем пустой текстовый файл и прописываем в нем примерно такие строки:
User-agent: *
Disallow: /wp-admin/
# не индексировать адрес административной панели входа в WordPress
Disallow: /privacy-policy/
# не индексировать страницу с политикой конфиденциальности
Sitemap: https://yoursite.com/sitemap.xml
# путь к карте сайта;
Часто в директивах есть служебные комментарии, которые веб-мастеры оставляют для себя и коллег:
User-agent: *
Allow: /
Host: www.yoursite.com
# Саня, если клиент не заплатит, через три дня загоняем весь сайт под запрет!
Автоматически
Если не чувствуете уверенности и боитесь наделать ошибок в robots.txt, воспользуйтесь онлайн-сервисами, которые после ввода/выбора ряда параметров на ваших глазах сформируют искомый файл.
После ввода ряда настроек, получаем итоговый файл robots.txt:
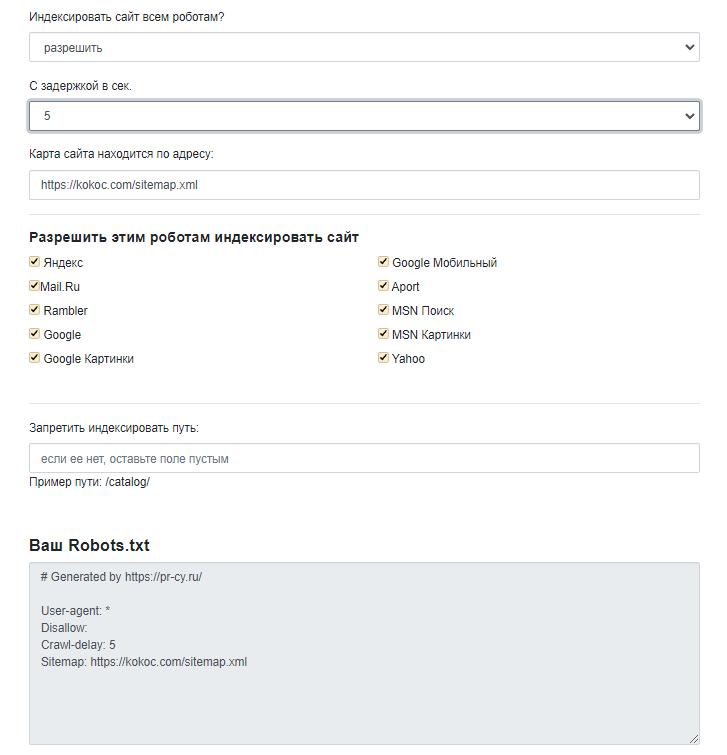
Как видите, в настройках мы не ставили запрет на обход определенных страниц. На реальном сайте необходимо всегда принимать во внимание, что не должно попасть в индекс.
Заходим на сайт и выбираем «Инструменты» → «Генераторы» → «Генератор robots.txt». На странице с инструментом выбираем нужный адрес, робота индексации. Также можно указать запрет определенных символов на страницах и целые страницы и папки.
Нужный текст формируется в режиме реального времени исходя из вводимых параметров.
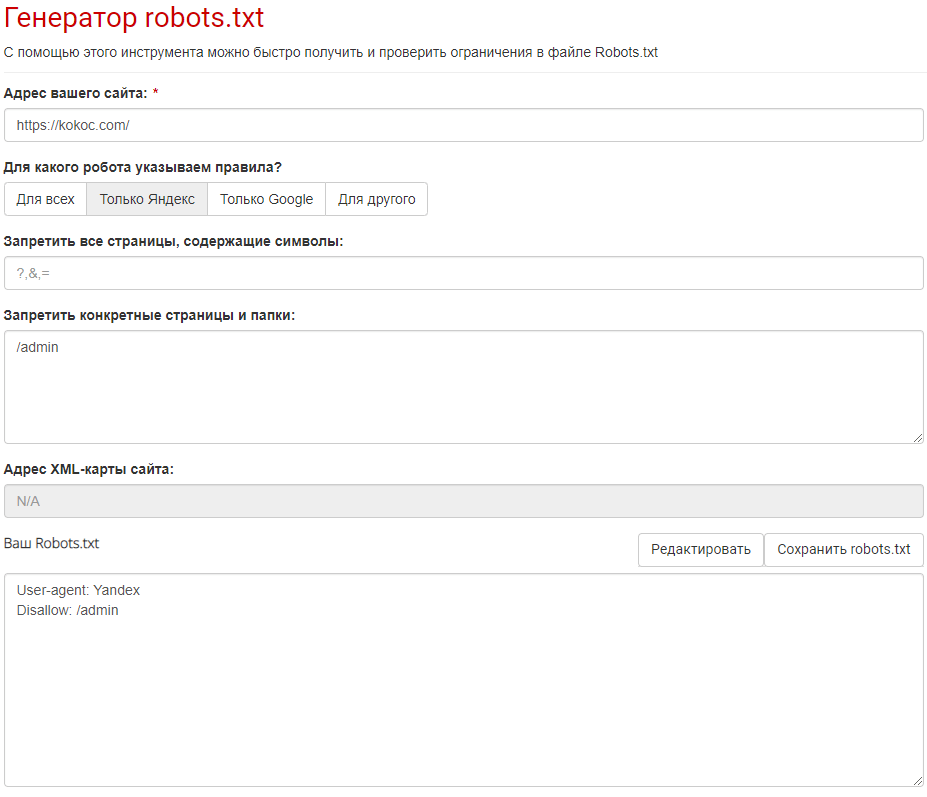
Я так и не смог понять, почему поле указания пути к карте сайта осталось неактивным.
На главной странице сайта надо найти «Онлайн-сервисы» (они точно есть в футере) и затем выбрать «Генератор Robots.txt».
Вводим домен сайта, имя робота, выбираем из списка страниц для запрета индексации основное зеркало сайта и путь к sitemap.xml:

Преимуществом этого сервиса является то, что под результирующим полем дается инструкция о том, что делать с полученным текстом дальше, и описываются все директивы.

Как запретить индексацию в robots.txt
Как мы уже сказали, файл можно использовать и для разрешения на индексацию всех страниц сайта, так и на полный запрет обхода.
Также можно закрывать от индексации разделы сайта выборочно — для разных роботов.
Если требуется, чтобы директива распространялась на всех роботов, нужно в конце первой строки прописать знак звездочки (*). Если только на определенного, тогда после директивы User-agent нужно указать его название.
Прописанные директивы относятся ко всем роботам, в конце первой строки ставится знак «*». При обращении к конкретному поисковику необходимо прописать его название в первой строке-директиве User-agent.
Как запретить индексацию сайта
Запретить индексацию каких-то страниц, разделов или всего сайта через директиву Disallow можно следующим образом.
User-agent: *
Disallow: /
# мы запретили доступ ко всем страницам сайта для всех роботов
Как закрыть страницу от индексации
User-agent: Googlebot
Disallow: /page
# мы запретили доступ робота Google ко всем страницам, начинающимся на “/page”
Сервисы проверки robots.txt
Рассмотрим для примера файл с сайта kokoc.com.
Яндекс.ВебмастерОткрываем сервис, переходим в раздел «Инструменты» → «Анализ robots.txt». Затем нужно ввести адрес проверяемого сайта и получить по нему все данные:
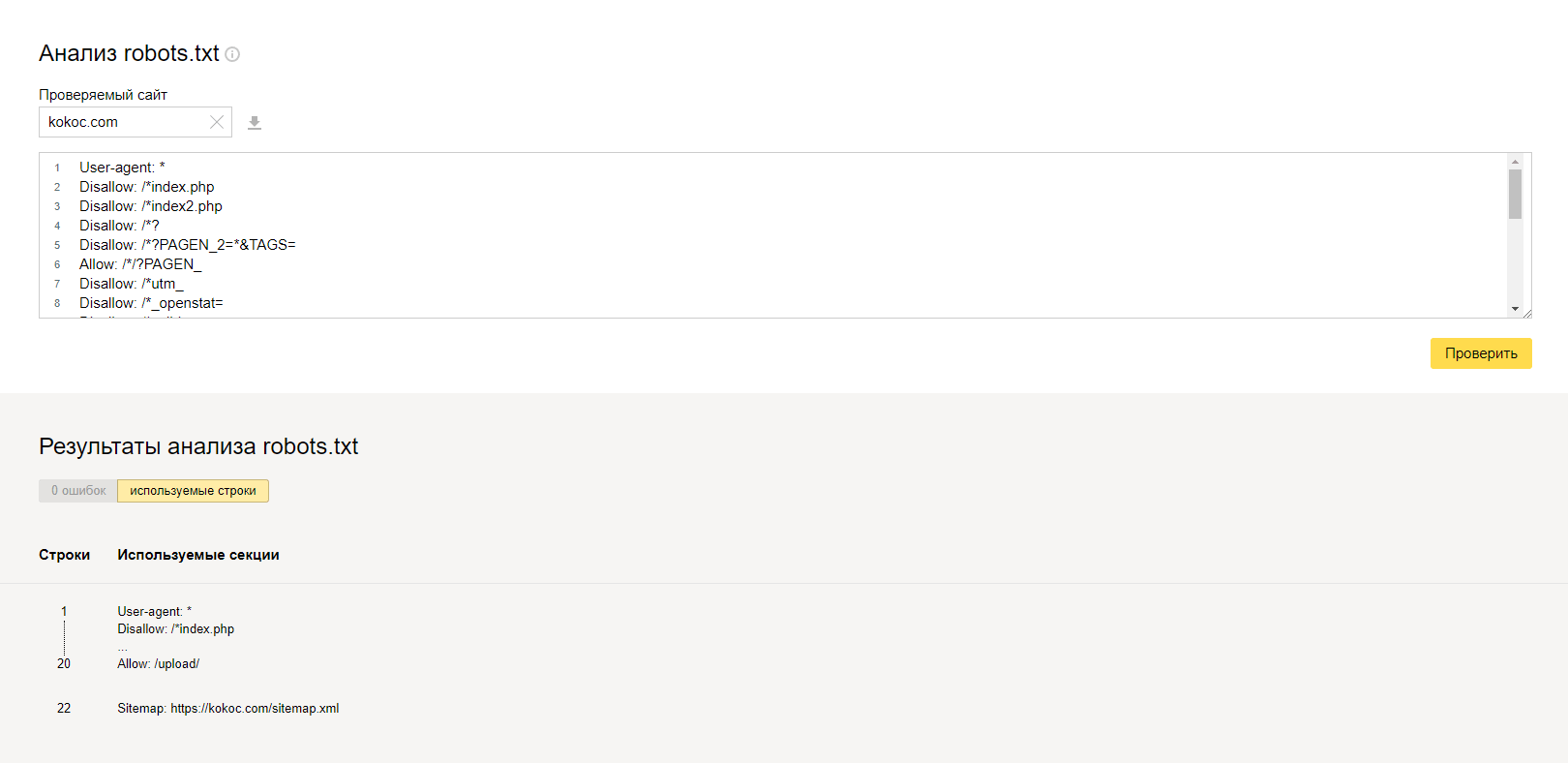
Как и ожидалось, ошибок в файле нет.
Google Search ConsoleУвы, но тут сервис предлагает выбрать объект проверки только из моих ресурсов, поэтому привожу пример его robots.txt:
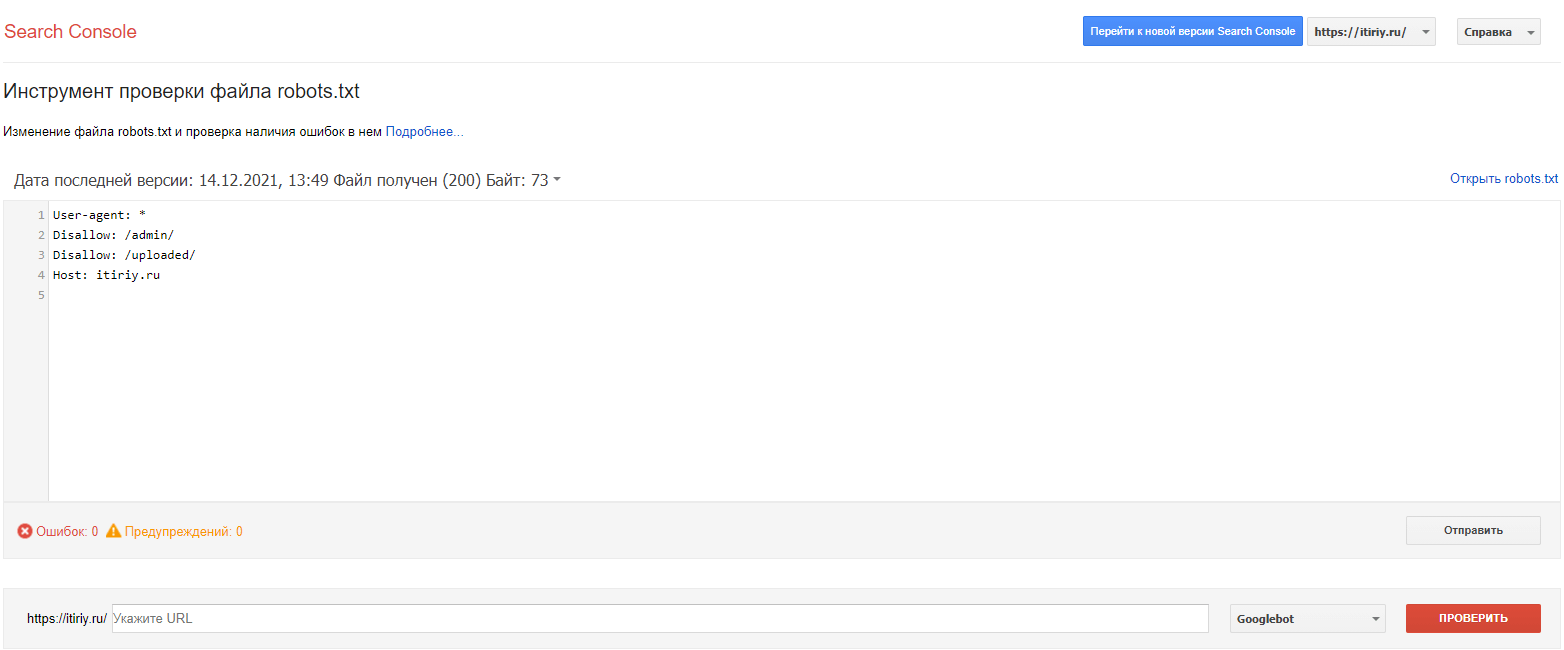
Радует, что проверка прошла успешно.
На главной странице сайта выбираем в меню «Инструменты» → «Все инструменты» → «Анализ robots.txt». Вводим целевой URL и получаем результаты:
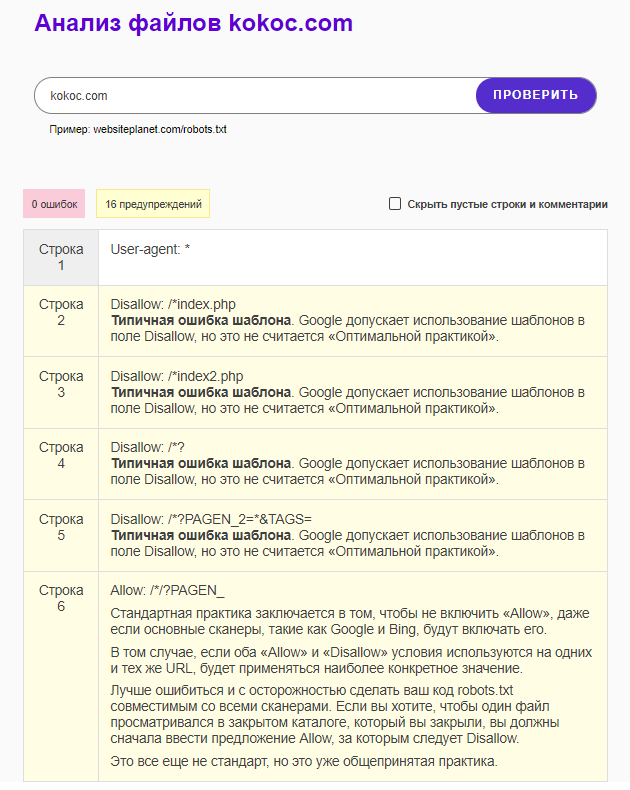
Пожалуй, это самый информативный из рассмотренных сервисов.
На главной странице сайта выбираем инструмент robots.txt Tester. В появившемся окне вводим целевой URL, выбираем из списка робота (можно выбрать всех). Нажимаем красную кнопку «TEST». Примечательно, что можно открыть файл в «живом» режиме и в режиме редактирования:
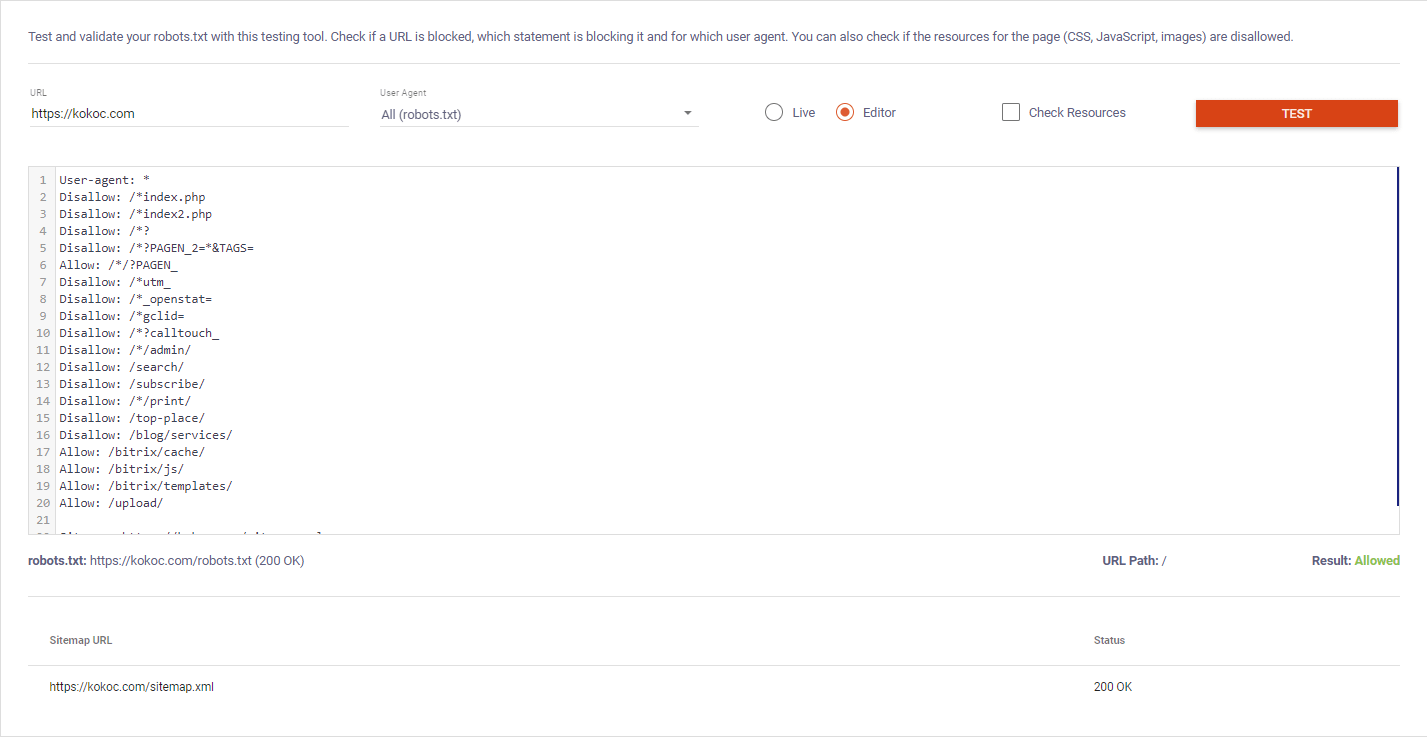
Сервис также показывает путь к карте сайта и ее статус.
На главной странице сервиса выбираем «Технический аудит» → «Проверка файла robots.txt». В окне проверки можно ввести как URL для получения файла сайта, так и URL для проверки. Полученный результат выглядит следующим образом:
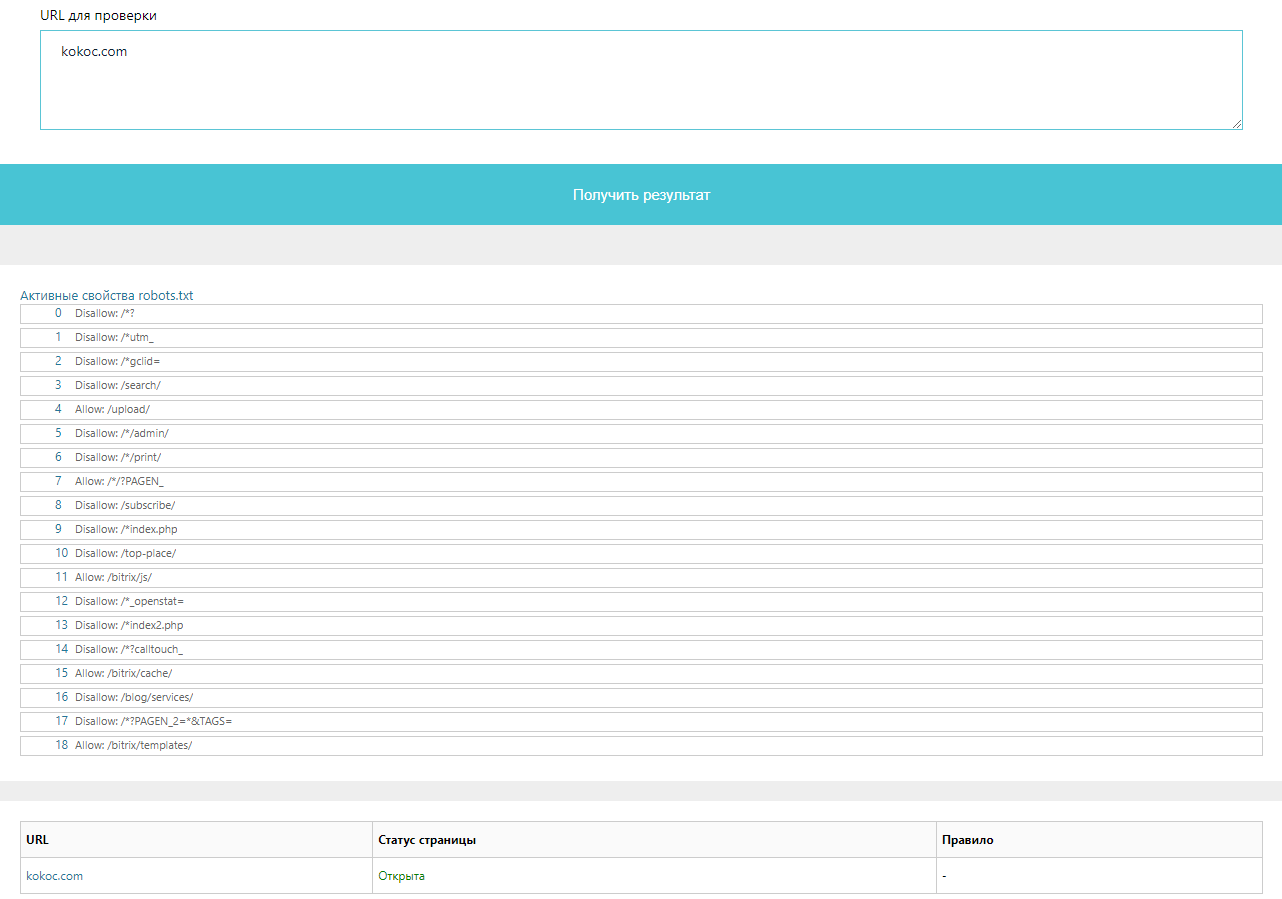
Особенностью сервиса является то, что можно выбрать как нужного робота, так и целевую CMS, на которой сделан сайт для проверки соответствующих директив.
Помните о роботах!
Robots.txt — это маленький файл, который несет в себе большие возможности для грамотных вебмастеров и SEO-специалистов и большие проблемы, если им не заниматься.
В конечном счете он экономит нагрузку на сервер и является одним из гарантов быстрой и корректной индексации вашего сайта. Поисковые системы очень уважают тех, кто соблюдает их требования.
выглядит следующим образом:



.png)

.png)
.png)

Комментарии (3)
Оставить комментарий