

Файл Robots.txt позволяет управлять индексацией вашего сайта. Он указывает поисковым роботам, по каким ссылкам можно переходить, точно также можно запретить/заблокировать индексацию определенных страниц через этот файл.
В целом правильная настройка robots.txt позволяет косвенно управлять краулинговым бюджетом интернет-ресурса. Из этой статьи вы узнаете про ошибки, допускаемые при составлении этого файла и нюансы правильной настройки.
- Основы robots.txt: технические требования, которые нельзя игнорировать
- Полный разбор всех директив robots.txt
- ТОП-15 ошибок в robots.txt, которые убивают трафик
- Как проверить robots.txt на ошибки
- Восстановление после ошибок и профилактика
- FAQ по robots.txt
- Заключение
- Коротко о главном
Основы robots.txt: технические требования, которые нельзя игнорировать
Robots.txt — это текстовый файл, который показывает поисковым роботам, как сканировать ваш сайт. Он защищает сайт и сервер от перегрузки из-за запросов поисковых роботов.
Если вы хотите заблокировать работу поисковых роботов, необходимо убедиться в корректности настроек. Это особенно важно, если вы используете динамические URL или другие методы, которые в теории генерируют бесконечное количество страниц.

Его можно использовать для множества целей:
- Блокировка сканирования поисковыми роботами определенных страниц. Они все еще могут появляться в поисковой выдаче, но без текстового описания. Контент не в формате HTML тоже не будет сканироваться.
- Блокировка медиафайлов для отображения в результатах поиска. Под медиафайлами понимаются изображения, видео и аудиофайлы. Если для файла предусмотрен общий доступ, он будет отображаться, но приватный контент не попадет в поисковую выдачу.
- Блокировка файлов ресурсов с неважными внешними скриптами. Если у страницы заблокирован файл ресурсов, поисковые роботы посчитают, что его не существовало вовсе. Это может сказаться на индексировании.
Использование robots.txt не позволит полностью запретить отображение страницы в результатах поиска. Для этого придется добавить метатег noindex в верхнюю часть страницы.
Теперь поговорим о технических особенностях файла. В таблице представлены основные требования:
|
Параметр |
Значения |
|
Формат файла |
.txt |
|
Кодировка |
UTF-8 без BOM |
|
Расположение |
Корневая директория сайта |
|
Отклик сервера |
ОК 200 |
|
Размер файла |
до 32 Кб |
Помимо перечисленного, все кириллические домены должны вписываться в файл с помощью Punycode.
Чтобы вам было проще проверить свой файл robots.txt, я подготовил краткий чек-лист для проверки:
- Формат файла — .txt.
- Кодировка UTF-8 без BOM.
- Сервер дает ответ 200.
- Все ссылки на кириллические домены даны в Punycode.
- Для каждого поискового робота настроены свои правила.
- Название файла в нижнем регистре.
- Размер файла до 32 Кб.
Полный разбор всех директив robots.txt
Robots.txt содержит в себе команды для поисковых роботов. Ниже я разберу более подробно все группы команд и расскажу, как они работают на практике.
User-agent: для кого пишем правила
В первую очередь, нам нужно показать, для какого поискового робота написаны правила. Для этого используется директива User-agent. Эту директиву распознают все поисковые системы. В таблице показано соответствие значений директивы и поисковой системы:
|
Поисковая система |
Возможные значения User-agent |
|
|
Googlebot, Googlebot-Image, Googlebot Mobile |
|
«Яндекс» |
YandexBot, YandexImages, YandexMobileBot |
|
Microsoft Bing |
Bingbot |
|
Mail.ru |
Mail.Ru |
|
Google Ads |
AdsBot-Google |
|
Google AdSense |
Mediapartners-Google |
Директива должна располагаться перед группой правил на которые действует. Это показано на скриншоте:

Учитывайте, что правила, указанные для конкретного бота, действуют только на него. Если вы закрыли определенные страницы от «Яндекса», это не сработает для Google. Потребуется делать отдельный блок правил.

Disallow и Allow: как правильно запрещать и разрешать
Для запрета индексирования применяется директива Disallow. Она показывает, что поисковый робот не должен индексировать эту страницу, папку сайта или полностью ресурс.
Правильный синтаксис директивы выглядит так:
Disallow:
Если нам нужно закрыть от индексирования весь сайт, используют такой формат директивы:
Disallow:/
В случае когда нам нужно закрыть от индексации какие-нибудь разделы сайта с одинаковым началом URL, применяют такую конструкцию, где после слеша вписывают знак *, например:
Disallow:*/
Иногда нужно запретить индексирование адреса с точным окончанием. Тогда используют знак доллара $. Выглядит директива вот так:
Disallow:/admin$
Для разрешения доступа поисковых роботов к определенным разделам сайта используется директива Allow. Здесь также указывается путь к документу после двоеточия, остальные правила аналогичны, применяются знаки * и $. Вот пример разрешения для поискового робота.
Allow:*/.pdf
Иногда встречаются ситуации, когда один и тот же раздел сайта отмечен обеими директивами. В таком случае за редким исключением действует правило: более длинный прописанный путь имеет приоритет. Например, в показанном ниже примере, приоритет будет у директивы Allow, так как там путь прописан лучше.
Disallow:*/wasa
Allow:*/catalog/wasa
На скриншоте показан пример группы директив с разными параметрами.
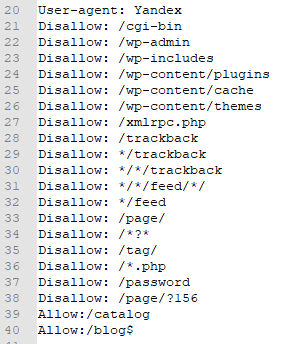
Разные поисковые роботы имеют свои особенности в приоритетах для директив. К примеру, Googlebot при наличии двух директив одновременно, отдаст предпочтение Disallow, а вот «Яндекс» учитывает точность указания пути к разделу сайта.
Sitemap: указываем путь к карте сайта
Чтобы поисковые роботы быстрее находили файл Sitemap, необходимо указывать путь к нему в robots.txt. Нужно указывать полный путь, потому что этого требует синтаксис. Также указывают путь не только к стандартному формату карты сайта .xml, но и к сжатым форматам.

Обратите внимание, что все поисковые роботы учитывают эту директиву, поэтому ее указывают вне групп. Если путь к файлу указан неверно, роботы при сканировании эти строки пропустят.
Crawl-delay: замедляем роботов
Используется, чтобы можно было контролировать скорость переобхода сайта поисковыми роботами. Обычно делается с целью снизить нагрузку на сервер. После директивы указывается число, обозначающее время задержки между запросами в секундах.
Вот пример директивы с тайм-аутом 2 секунды:
Crawl-delay: 2
Но не все поисковые системы учитывают эту директиву. «Яндекс» учитывает ее при обходе, а Google игнорирует, предлагая использовать альтернативу в виде собственных инструментов в Search Console. Также не стоит выставлять слишком большие таймауты, это может привести к замедлению индексации.

Clean-param: инструкция для «Яндекса» по работе с динамическими URL
Директива упрощает индексацию поисковыми роботами динамических URL. Это дает возможность избежать появления дублированного контента в индексе. К примеру, если у вас к части контента может добавляться динамическая часть в адресе, директива показывает, что по этим адресам не нужно переходить для сканирования.
Приведу несколько примеров использования.
Можно исключать из индекса технические страницы, возникающие при посещении страниц интернет-магазина:
Clean-param: lot&order&filter /catalog/
Можно не учитывать при сканировании адреса, появляющиеся при индивидуальных сессиях:
Clean-param: session_id&cdd /
Если вы ведете пользователей на сайт через рекламные системы, можно закрыть от индексации адреса с UTM-метками:
Clean-param: utm_source&utm_medium&utm_campaign&utm_content&utm_term /catalog/
Основная особенность этой директивы состоит в том, что учитываются только URL с прописанным путем. Google игнорирует эту директиву, предлагая размечать страницы тегом canonical.
Host: устаревшая, но важная директива
Директива показывает основной адрес сайта. Разрабатывалась «Яндексом» для указания на основное зеркало сайта. Google и другие поисковые системы не учитывали эту стройку в файле robots.txt.
С 2018 года «Яндекс» тоже не учитывает эту директиву. Сейчас использование директивы Host — анахронизм.
Специальные символы: *, $ и #
Как уже упоминалось выше, к директивам добавляются специальные символы. Ниже покажу несколько примеров их применения с объяснениями.
Один из распространенных спецсимволов — это звездочка (*). Оператор показывает, что в URL до указанного пути может быть любое количество значений. В примере ниже видно, что робот должен игнорировать все адреса заканчивающиеся на такие значения:
Disallow:*/catalog/sort-tomat/
Другой спецсимвол — $. Он фиксирует завершение URL. Вот пример, запрещающий индексацию всех адресов содержащих файлы .docs:
Disallow:$.docs
Иногда требуется дать комментарий к какой-то директиве. Для этого существует оператор #, с помощью которого обозначают строки, которые необходимо игнорировать:
#Директивы для «Яндекс»
User-agent:YandexBot
Символ ставится в начале текста и действует до завершения строки.

ТОП-15 ошибок в robots.txt, которые убивают трафик
Теперь разберу ошибки, встречающиеся в оформлении файла robots.txt. Некоторые из них могут сильно ухудшить индексацию.
Неверное расположение файла
Поисковые роботы могут найти файл robots.txt, только если он расположен в корневом каталоге. Поэтому домен, например, .ru, и название файла robots.txt в URL должна разделять одна косая черта. Чтобы исправить эту ошибку, перенесите robots.txt в корневой каталог. Для этого потребуется доступ к серверу. Некоторые системы управления содержимым по умолчанию загружают файл в подпапку с медиафайлами или подобные. Чтобы файл попал в нужное место, придется обойти эту настройку.
Неправильное использование * и $
При использовании спецсимволов стоит придерживаться минимализма. Спецсимволы могут потенциально наложить ограничения на большую часть сайта. Неправильное использование звездочки может привести к блокировке поискового робота. Чтобы решить проблему с неправильным оператором, нужно его найти и переместить или удалить.
Блокировка CSS и JS файлов
Ограничение доступа к внутреннему JavaScript коду и Cascading Style Sheets (CSS) для поисковых роботов кажется логичным шагом. Однако поисковым роботам Google требуется доступ к CSS и JavaScript файлам, чтобы корректно сканировать HTML и PHP страницы. Если страницы сайта странно отображаются в поисковой выдаче, проверьте, не заблокирован ли доступ поискового робота к этим внутренним файлам. Удалите соответствующую строку из файла robots.txt. Если же вам нужна блокировка определенных файлов, вставьте исключение, которое даст поисковым роботам доступ только к нужным материалам.
Случайная блокировка всего сайта (Disallow: /)
В этом случае поисковая система получает команду — не индексировать сайт. Ошибка исправляется удалением такой строки из файла.
Отсутствие пути к Sitemap
Этот пункт относится к SEO больше всего. Файл sitemap.xml дает роботам информацию о структуре сайта и его главных страницах. Поэтому есть смысл добавить его в файл robots.txt. Его поисковые роботы Google сканируют в первую очередь. Строго говоря, это не ошибка, и в большинстве случаев отсутствие ссылки на sitemap в robots.txt не должно влиять на функциональность и внешний вид сайта. Но если вы хотите улучшить продвижение, дополните файл robots.txt.
Устаревший noindex в файле
Эта ошибка часто встречается у сайтов, которым уже несколько лет. Google в сентябре 2019 года перестал выполнять команды метатега noindex в файле robots.txt. Если ваш файл был создан до этой даты или содержит метатег noindex, скорее всего, страницы будут индексироваться Google. Чтобы решить проблему, примените альтернативный метод. Вы можете добавить метатег robots в элемент страницы <head>, чтобы остановить индексацию.
Неправильный синтаксис (несколько каталогов в одном Disallow)
При ошибочном указании пути к документа сайта поисковый робот просто не найдет к нему дорогу. Исправляется это прописыванием правильного пути.
Использование кириллицы в путях без Punycode
Поисковые роботы не учитывают кириллические символ при обходе, а значит не могут правильно применять директивы. Обязательно используйте Punycode (метод перевода кириллических символов в понятные для серверов латинские обозначения) для указания пути к документам.
Конфликт директив Allow и Disallow
Если директивы полностью одинаковы, они могут вообще не учитываться роботами. В случае с Google он будет учитывать только директиву Disallow, то есть просто не будет индексировать.
Путаница с регистрами (case-sensitivity)
Если указан неправильный регистр в пути к файлам, это не позволит поисковым роботам их учитывать.
Открытые для индексации служебные разделы (админка, результаты поиска)
Запрет сканирования поисковыми роботами рабочих страниц — серьезная ошибка. Как и предоставление им доступа к страницам, находящимся в разработке. Включите запрещающие инструкции в файл robots.txt, если сайт находится на реконструкции. Тогда пользователи не увидят «сырой» вариант.
Неверно указанная директива Host
Несмотря на то, что эта директива уже не учитывается, при неправильном адресе это может мешать индексации.
Чрезмерно высокий Crawl-delay
Так вы сильно замедляете индексацию. Вы можете вообще остановить индексирование вашего сайта.
Использование заглавных букв в имени файла (ROBOTS.TXT)
Поисковые роботы ориентируются только на файлы с названием в нижнем регистре!
Отсутствие пустой строки Disallow: для секций, где ничего не запрещено
В этом случае нарушается синтаксис файла, а значит поисковые роботы считают, что он создан неправильно и лучше robots.txt игнорировать.
Также в топ ошибок входит закрытие от сканирование раздела вместо страницы. Часто забывают добавить в конце символ $.
В остальном, больше недочеты. Оптимизаторы иногда забывают про регистры, про смысл файла (сканирование, а не индексация), добавить все файлы sitemap.


Как проверить robots.txt на ошибки
Для проверки используются инструменты поисковых систем. Ниже разберу самые удобные варианты для проверки.
Проверка в Google Search Console
Чтобы посмотреть отчет по robots.txt, заходим в Search Console, и нажимаем на ссылку«Настройки». В списке находим строку robots.txt и жмем на кнопку «Открыть отчет».
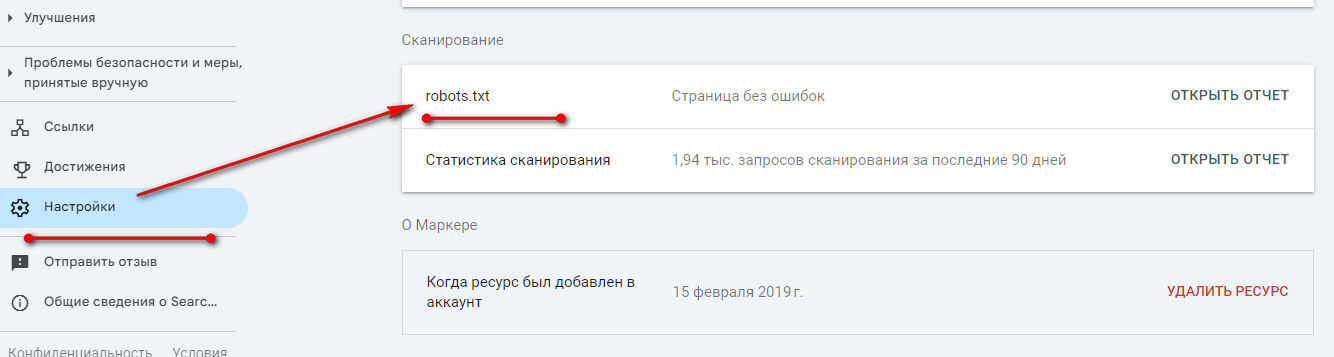
Открывается список всех файлов, доступных для проверки. Тут же показано число ошибок и проблем. Чтобы посмотреть проблемы жмем на метку в столбце «Проблемы».
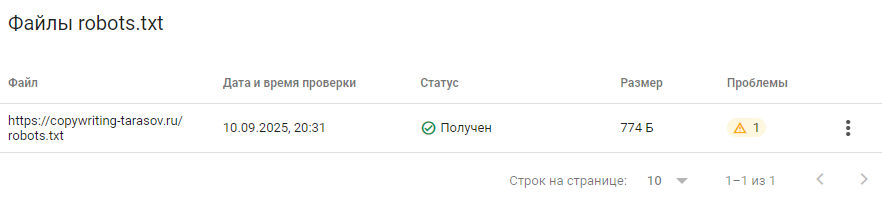
В открывшемся окне смотрим, какие параметры «не нравятся» Google. В моем примере это директива Host:
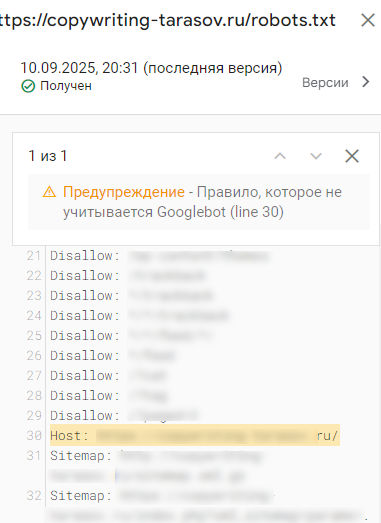
Обратите внимание, что некоторые ошибки, считающиеся таковыми в Google, будут необходимыми строками для «Яндекса».
Проверка в «Яндекс Вебмастере»
Аналогичный инструмент предлагает и «Яндекс Вебмастер». Найти его можно в меню «Инструменты». Кликаем на ссылку «Анализ robots.txt»:
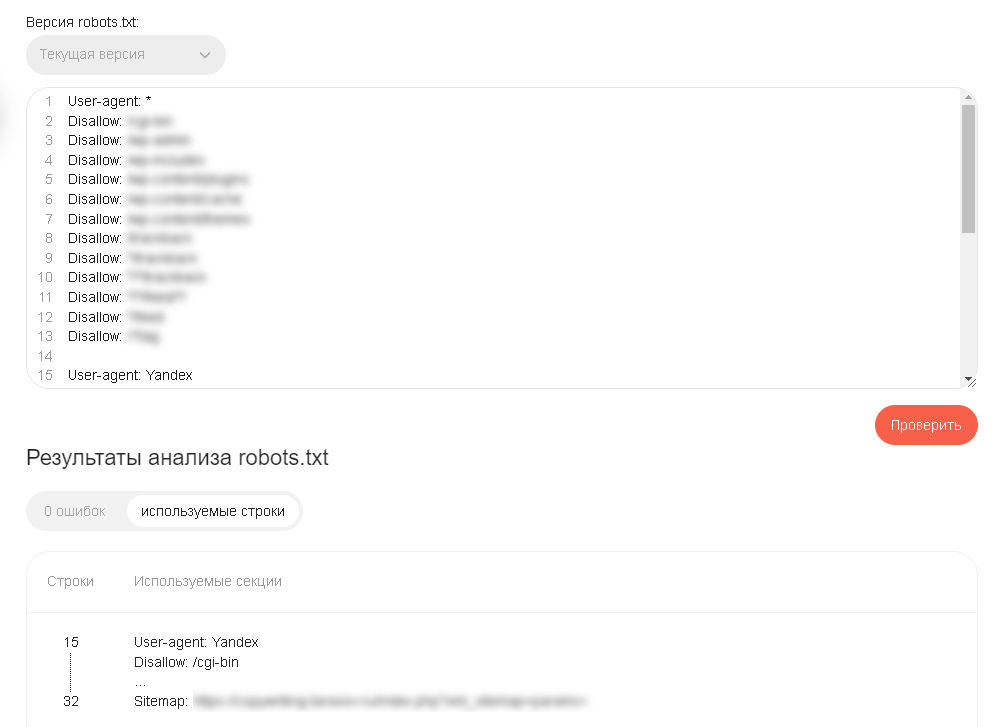
Открывается окно, где показан текущий вариант файла. «Яндекс» загружает его с проверяемого сайта. Если вам нужно проверить альтернативную версию, вставляем код в поле и нажимаем кнопку «Проверить». В отчете будут возможные ошибки и используемые «Яндексом» строки файла.
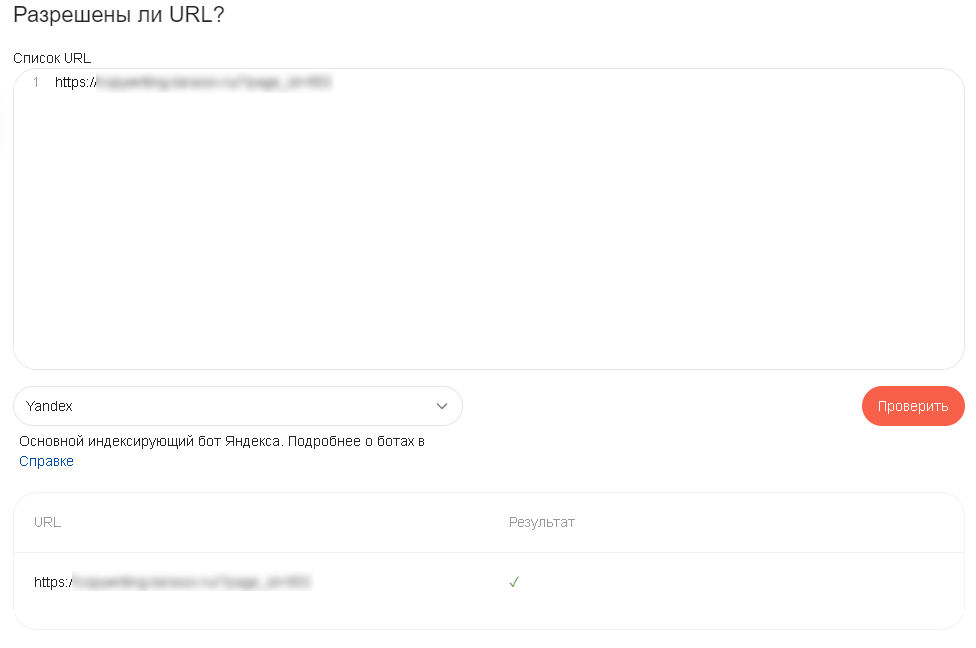
Есть возможность проверить конкретный URL на разрешение к индексации. Для этого опускаемся чуть ниже окна с проверкой robots.txt и вставляем список URL. Потом нажимаем кнопку «Проверить». В отчете можно увидеть открыта ли страница для индексирования.
В целом инструмент для проверки у «Яндекс Вебмастера» более информативен. Есть возможность проверки отдельных адресов.
.jpg)
Восстановление после ошибок и профилактика
Если ошибка в файле robots.txt повлияла на отображение в поисковой выдаче, самое главное — скорректировать файл и подтвердить, что новые правила дают нужный эффект. Проверить это можно с помощью инструментов для сканирования, например, Screaming Frog.
Когда убедитесь, что robots.txt работает верно, запросите повторное сканирование поисковыми роботами: в этом поможет Google Search Console. Добавьте обновленный файл sitemap и запросите повторное сканирование страниц, которые пострадали.
К сожалению, нет конкретного срока, в который поисковый робот проведет сканирование и страницы начнут нормально отображаться в поисковой выдаче. Все, что остается — быстро выполнить необходимые шаги и ждать, когда поисковый робот просканирует сайт.
Ошибки с файлом robots.txt решаются относительно просто, но лучшим лекарством от них станет профилактика. Редактируйте файл аккуратно, привлекая опытных разработчиков, дважды все проверяйте и, если это актуально, послушайте мнение второго специалиста.
Если есть возможность, протестируйте изменения в песочнице, прежде чем применять их на реальном сервере.
Песочница — специально выделенная (изолированная) среда для безопасного исполнения компьютерных программ.
Это позволит избежать непроизвольных ошибок. И помните: если самое страшное уже случилось, не поддавайтесь панике. Проанализируйте проблему, внесите необходимые изменения в файл robots.txt и отправьте запрос на повторное сканирование. Скорее всего, нескольких дней будет достаточно, чтобы вернуться на прежние позиции в поисковой выдаче.
FAQ по robots.txt
Работа с robots.txt часто вызывают вопросы у неопытных пользователей. Отвечу на некоторые из них.
Что будет, если файла нет?
В принципе сайт будет индексироваться. Только роботы будут обходить его хаотично, без учета важности страниц. В результате вы можете получить ситуацию когда технические страницы проиндексированы, а главная страница не находится в индексе.
Как robots.txt влияет на краулинговый бюджет?
Правильная настройка файла позволяет управлять краулинговым бюджетом. Фактически закрывая от переобхода ненужные страницы, мы экономим краулинговый бюджет, перераспределяя его между важными для нас документами.
Что будет если закрыть сайт от индексации в robots.txt?
Сайт постепенно выпадет из индекса. Ко мне на аудит приходил предприниматель, у которого сайт внезапно перестал индексироваться. Оказывается, что админ сайта зачем-то запретил его индексацию в «Яндексе». Через пару недель сайт полностью «ушел» из индекса «Яндекса».
Заключение
Необходимо регулярно проверять правильность работы файла robots.txt — особенно если вы проводили какие-то работы на сайте. К примеру, не забудьте снять запрет индексации со страниц после того как вы их полностью сделаете.
В целом файл robots.txt позволяет эффективно управлять индексацией сайта. Его нужно постоянно поддерживать в актуальном состоянии.
Коротко о главном
- Robots.txt позволяет управлять краулинговым бюджетом и упрощает индексирование.
- Для управление поисковыми роботами используются директивы и операторы.
- Чтобы избежать проблем с индексацией, проверяйте работу файла robots.txt через сервисы поисковых систем — Google Search Console и «Яндекс Вебмастер.»
- Важно уделять внимание правильности прописанных в файле путей к документам сайта.

.png)

.png)
.png)

Комментарии
Комментариев пока нет. Будьте первым!
Оставить комментарий