

Сбор информации требуется для решения конкретных бизнес-задач. Анализ конкурентов, мониторинг цен на рынке, агрегация контента — всё это требует автоматизации. Вручную обрабатывать сотни веб-страниц долго и нерентабельно.
Для извлечения нужных сведений эффективнее применять специализированные программы. В моей практике регулярно возникают подобные задачи. Гораздо проще выгрузить базу, проанализировать среднюю стоимость продукта и принять решение, имея на руках полный массив цифр, а не разрозненные фрагменты. В этой статье подробно разберем, что такое парсинг, для чего он применяется маркетологами и аналитиками, а также какие инструменты помогают настроить этот процесс.
Парсинг сайтов — это автоматизированное извлечение данных из HTML-кода или DOM-дерева с последующим сохранением в структурированный формат (CSV, JSON, Excel). Процесс кардинально отличается от краулинга (который просто обходит ссылки для индексации) и от работы через API (где платформа предоставляет официальный, задокументированный шлюз). Скрипт отправляет HTTP-запрос, получает содержимое и вытаскивает конкретные элементы по заданным правилам.

- Что такое парсинг
- Зачем нужен парсинг данных
- Плюсы и минусы
- Как происходит парсинг данных
- API или парсинг: что выбрать
- Обход антибот-систем и этика
- Типовые сложности и решения
- Классификация инструментов
- Сервисы парсинга
- Пример парсера на Python
- Сделать самому или заказать
- Законно ли парсить данные
- Часто задаваемые вопросы
Что такое парсинг
Технически процесс представляет собой синтаксический анализ. Программа-парсер обращается к целевому ресурсу, загружает исходный код страниц и ищет заданные паттерны. Для точного выделения узлов применяются не языки программирования, а специальные языки запросов — XPath или CSS-селекторы.
Современный парсинг в интернете усложнился. Большинство популярных платформ используют технологию Single Page Application (SPA). Поэтому для получения контента часто требуется Server-Side Rendering (SSR) или применение headless-браузеров, которые имитируют действия реального пользователя и выполняют JavaScript перед тем, как спарсить нужный текст.
Зачем нужен парсинг данных
Автоматический сбор применяется в различных сферах бизнеса. Рассмотрим основные сценарии использования:
- Анализ сайтов конкурентов. Позволяет быстро собрать ассортимент, характеристики и цены, избегая рутинного просмотра чужих каталогов.
- Мониторинг изменений. Отслеживание динамики прайс-листов в период сезонных распродаж или перед праздниками.
- Технический аудит собственного ресурса. Поиск битых ссылок, проверка корректности заполнения метатегов (Title, Description) и заголовков H1.
- Заполнение карточек товара. Агрегация технических характеристик от официальных производителей для импорта в собственный интернет-магазин.
- Генерация базы лидов. Извлечение открытых контактных данных (email, телефон) профильных компаний из публичных справочников.
Задачи по ролям
| Роль | Объект сбора | Типы данных | Результат |
|---|---|---|---|
| SEO-специалист | Поисковая выдача, сайты | Позиции, теги, статус-коды | Оптимизация структуры, поиск ошибок |
| Маркетолог | Соцсети, отзовики | Упоминания бренда, отзывы | SERM, корректировка рекламной стратегии |
| E-commerce менеджер | Маркетплейсы | Цена, наличие, рейтинг | Динамическое ценообразование |
| Аналитик | Открытые реестры | Финансовые показатели, объемы | Построение дашбордов и прогнозов |
Объекты и форматы выгрузки
| Объект | Извлекаемые поля | Формат выгрузки |
|---|---|---|
| Товар | Название, артикул, стоимость, фото | CSV, XML |
| Статья (блог) | Заголовок, автор, дата, текст | JSON, TXT |
| Контакты | Адрес, номер телефона, почта | Excel (XLSX) |
Плюсы и минусы
Любой маркетинговый или технический инструмент имеет свои ограничения и преимущества. Важно оценивать их до старта проекта.
Преимущества:
- Экономия времени. Отпадает необходимость вручную копировать информацию.
- Масштабируемость. Можно проанализировать миллионы URL за несколько часов.
- Точность. Программный алгоритм исключает человеческий фактор — скрипт не пропустит нужный элемент, если селекторы заданы верно.
- Удобный экспорт. Собранный массив легко конвертируется в требуемый формат (из JSON в таблицу базы данных).
Недостатки и риски:
- Защита серверов. Многие IP-адреса блокируют подозрительную активность, ограничивая доступ к содержимому.
- Капча. Появление проверочных окон замедляет или полностью останавливает загрузку.
- Зависимость от верстки. Любое изменение структуры HTML-кода на стороне донора требует переписывания правил извлечения.
Как происходит парсинг данных
Процесс состоит из нескольких последовательных шагов, формирующих полноценный ETL-пайплайн (Extract, Transform, Load).
- Настройка и отправка запроса. Задаются стартовые URL. Формируются HTTP-заголовки (User-Agent, Accept), подключаются прокси-серверы для распределения нагрузки.
- Получение ответа и рендеринг. Сервер возвращает веб-страницу. Если сайт использует динамическую подгрузку, запускается headless-браузер для выполнения скриптов.
- Извлечение (Extract). Применяются правила поиска. Алгоритм находит нужные теги и забирает текстовое содержимое или атрибуты (например, ссылки на изображения).
- Очистка и нормализация (Transform). Удаляются лишние пробелы, HTML-сущности. Цены приводятся к единому числовому виду, даты стандартизируются.
- Логирование и обработка ошибок. Фиксируются сбои. При получении кода 429 (Too Many Requests) применяется метод экспоненциальной задержки (exponential backoff) — паузы между попытками увеличиваются.
- Выгрузка (Load). Готовый датасет сохраняется в файл или отправляется по API во внутреннюю CRM-систему компании.
API или парсинг: что выбрать
Часто возникает дилемма: использовать официальный шлюз или писать собственный скрейпер. Выбор зависит от задачи и доступности ресурсов.
| Критерий | API | Парсинг |
|---|---|---|
| Доступность | Официальный канал | Любые публичные страницы |
| Полнота | Ограничена документацией разработчика | Всё, что видит пользователь в браузере |
| Стабильность | Высокая (изменения версионируются) | Низкая (зависит от редизайна) |
| Легальность | Регулируется договором (SLA) | Требует проверки robots.txt и законов |
| Стоимость | Оплата за лимиты запросов | Затраты на сервера, прокси и поддержку |
| Скорость старта | Быстрая интеграция | Требует написания кода или настройки ПО |
API идеально подходит для стабильной синхронизации остатков с маркетплейсами. Скрейпинг незаменим, когда официального доступа нет, лимиты слишком дорогие, либо требуется собрать агрегированную аналитику по всему рынку.
%201.png)
%201.png)
%201.png)
%201.png)
%201.png)
Обход антибот-систем и этика
Современные ресурсы активно защищаются от автоматизированного сбора. WAF (Web Application Firewall) анализирует поведенческие факторы и блокирует ботов. Для стабильной работы применяют ряд технических решений, которые необходимо использовать этично, не создавая DDoS-нагрузку.
Ротация IP-адресов. Использование пула резидентных или мобильных прокси позволяет распределить запросы, имитируя обращения от разных пользователей.
Подмена отпечатков (Fingerprinting). Смена User-Agent, настройка корректных заголовков и имитация реального разрешения экрана снижают вероятность блокировки.
Управление задержками. Внедрение рандомизированных пауз между переходами. Если сервер возвращает заголовок Retry-After, скрипт обязан приостановить работу на указанное время.
Решение капчи. Интеграция сторонних сервисов распознавания применяется только в крайних случаях, когда это не нарушает прямых запретов площадки.
Типовые сложности и решения
| Проблема | Симптомы | Решение |
|---|---|---|
| Блокировка по IP | Ошибки 403 Forbidden, таймауты | Подключение ротационных прокси-серверов |
| Изменение верстки | Пустые значения в итоговом файле | Настройка алертов, обновление XPath-селекторов |
| Динамический контент | В коде есть скрипты, но нет текста | Переход на Selenium, Playwright или Puppeteer |
| Мусорные данные | Символы юникода, неверные форматы | Внедрение этапа валидации и регулярных выражений |
Классификация инструментов
Рынок предлагает множество решений. Их можно разделить на три основные категории:
- Десктопные программы. Устанавливаются на ПК. Примеры: Screaming Frog SEO Spider, Netpeak Spider, Comparser. Отлично подходят для технического аудита.
- Облачные no-code платформы. Работают через браузер, не требуют навыков программирования. Позволяют визуально кликать на элементы.
- Библиотеки и фреймворки. Решения для разработчиков. Популярный стек на Python включает Requests, BeautifulSoup и Scrapy.
Сервисы парсинга
Рассмотрим популярные платформы, которые помогают маркетологам и SEO-специалистам.
Import.io
Сайт: https://www.import.io/
Мощный зарубежный scraper. Легко извлекает информацию и предоставляет её в виде готовых таблиц. Сервис умеет на лету создавать API на основе собранного массива. Подписка стартует от 399$ в месяц. Цены, доступные методы оплаты и условия использования прокси проверяйте на официальном сайте вендора перед покупкой.
Парсер объявлений о продаже автомобилей
Сайт: https://tech-key.ru/products
Отечественный продукт для мониторинга досок объявлений. Умеет интегрироваться с внутренними CRM. Обновление базы происходит автоматически раз в сутки. Стоимость составляет 20000 рублей ежемесячно. Включен в реестр российского ПО.
Mozenda
Сайт: https://www.mozenda.com/
Платформа корпоративного уровня. Функционирует с 2007 года. Интерфейс позволяет настраивать сложную логику переходов. Базовый клиент работает под Windows. Платные тарифы рассчитываются индивидуально под конкретный объем сканирования.
КОМПАС-ГУРУ (COMPASS GOORU)
Сайт: https://compas-goo.ru/

Специализированный инструмент для работы с поисковой выдачей. Встроенные алгоритмы помогают структурировать семантику. Минимальный тариф обойдется в 1500 рублей. Присутствует в реестре отечественного софта.
«Диггернаут»
Сайт: https://www.diggernaut.ru/

Облачный сервис с визуальным конструктором. Предлагает бесплатный план с жесткими лимитами по трафику. Платные версии для малого бизнеса варьируются от 700 до 4200 рублей. Команда также берет проекты на заказ.
ParserOK
Сайт: https://parserok.ru/
Десктопное приложение. Умеет выгружать контент напрямую в таблицы. Предусмотрена демо-версия на 10 дней. Базовая лицензия стоит около 4000 рублей. Точные условия привязки ключей к железу уточняйте в технической поддержке.
ParseHub
Сайт: https://www.parsehub.com/
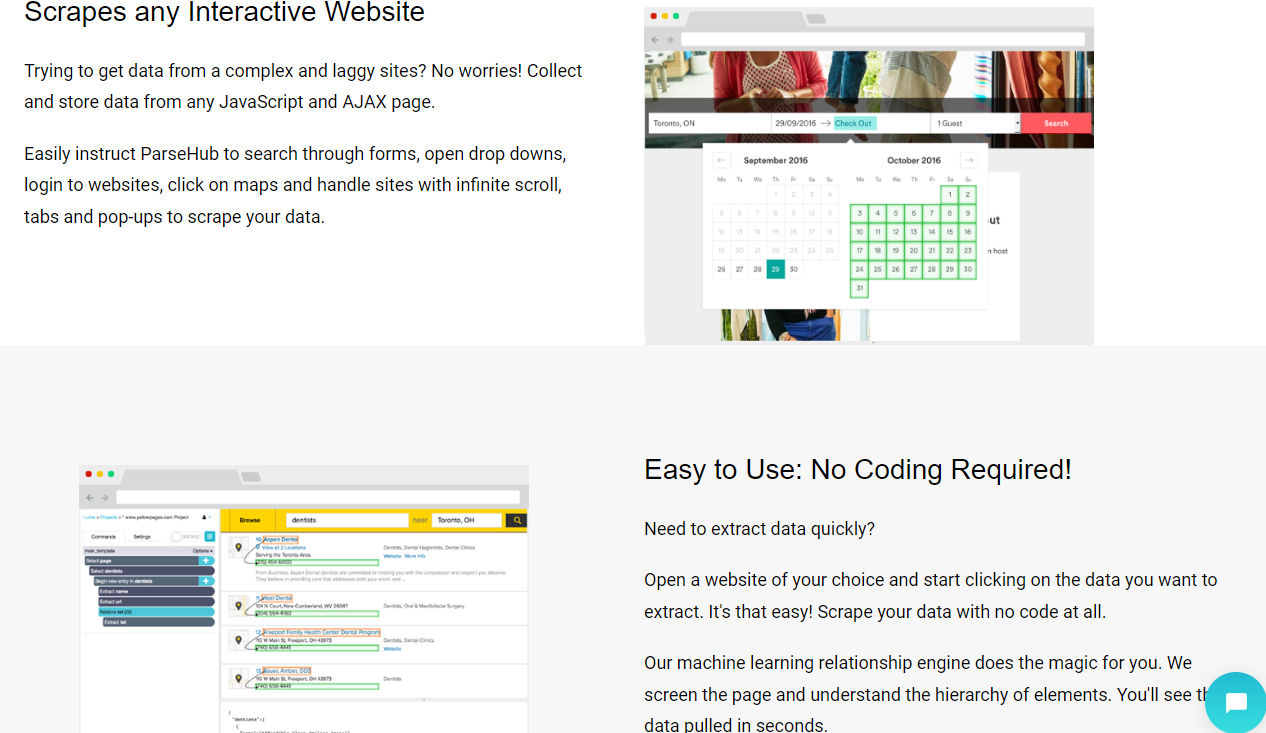
Универсальный инструмент. Поддерживает сложные сценарии: клики, скроллинг, авторизацию. Доступен триал на 14 дней. Минимальный платный пакет обойдется в 99$.
Пример парсера на Python
Для понимания механики приведу базовый авторский скрипт. Он демонстрирует, как с помощью популярных библиотек можно получить заголовок H1.
import requests
from bs4 import BeautifulSoup
url = 'https://example.com'
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('h1').text
print(f'Заголовок: {title}')
else:
print('Ошибка доступа')
Этот код — лишь основа. В реальных боевых условиях потребуется добавить обработку исключений, работу с прокси и сохранение в базу.

Сделать самому или заказать
Выбор подхода зависит от масштаба. Если нужно разово спарсить 500 страниц простого блога — используйте готовый платный софт или напишите скрипт самостоятельно. Это займет пару часов.
Если задача подразумевает ежедневный мониторинг 100 000 карточек на маркетплейсах с обходом сложной капчи и динамических токенов — целесообразно делегировать работу профильному агентству. Поддержка собственной инфраструктуры (сервера, покупка прокси, постоянная актуализация селекторов) обойдется дороже абонентской платы подрядчику.
Законно ли парсить данные
Сбор публичной информации не запрещен напрямую, однако процесс строго регламентируется рядом правовых и технических норм. Нельзя просто скачать всё подряд.
Правила площадки. Всегда проверяйте директивы в файле robots.txt. Если владелец ресурса запретил сканирование определенных директорий (Disallow), это требование нужно уважать. Также изучайте пользовательское соглашение (Terms of Service).
Персональные данные. Согласно 152-ФЗ, обработка ФИО, телефонов и email-адресов граждан РФ без их явного согласия запрещена. Тот факт, что человек оставил свой номер в открытом доступе в соцсети, не дает вам права добавлять его в свою базу для спам-рассылки.
Авторское право и коммерческая тайна. Копирование уникальных авторских статей для публикации на своем ресурсе нарушает ГК РФ (ст. 1259). Обход платных подписок (paywall) классифицируется как неправомерный доступ к компьютерной информации.
Часто задаваемые вопросы
Можно ли парсить любой сайт в интернете?
Нет. Необходимо предварительно изучить robots.txt и юридические условия использования конкретной площадки.
Нужен ли программист, чтобы собрать базу?
Для типовых задач достаточно визуальных no-code решений. Сложные многоуровневые проекты с авторизацией требуют написания кастомных скриптов.
Что делать, если целевой ресурс блокирует запросы?
Необходимо снизить скорость обращений, внедрить ротацию IP-адресов и настроить корректные HTTP-заголовки.
Сколько стоит внедрение парсинга?
Бюджет варьируется от нуля (при использовании open-source библиотек) до сотен тысяч рублей в месяц за enterprise-решения с поддержкой SLA.
Чем парсинг отличается от официального API?
API предоставляет структурированный доступ по правилам владельца с гарантией стабильности. Парсер работает с фронтендом и ломается при любом редизайне.
Разрешено ли собирать контакты для холодных продаж?
Сбор персональных данных без согласия субъекта является прямым нарушением законодательства (152-ФЗ).
В каком виде лучше хранить результаты?
Для небольших объемов подойдет Excel или CSV. Для Big Data используют реляционные базы или NoSQL решения с обязательным контролем дублей.
Нужно ли дорабатывать код со временем?
Да. Любое изменение в структуре DOM-дерева донора требует актуализации поисковых селекторов.
Коротко о главном
- Парсинг — это инструмент аналитики, а не воровство чужого контента.
- Извлекать можно только ту информацию, которая находится в легальном открытом доступе.
- Автоматизация сокращает время на рутину с недель до нескольких минут.
- Для любой задачи (от SEO-аудита до ценообразования) существует готовый программный продукт.




.png)

.png)
.png)

Комментарии (8)
Оставить комментарий