

Данные называют «нефтью XXI века». Это и неудивительно: информация стоит больших денег. Вы наверняка догадываетесь, что эти данные могут быть полезными не только бизнесу, но и обычным людям. Проводник между данными и людьми — Data Scientist — ученый, который знает про данные абсолютно все.
- Что такое Data Science
- Зачем и какому бизнесу нужна Data Science
- Кто такой специалист Data Science
- Чем занимается специалист по Data Science
- Должностные обязанности специалиста по Data Science
- Карьерный путь в Data science: от Junior до Senior
- Где искать заказы специалисту Data Science
- Инструменты Data Science
- Что нужно знать специалисту Data Science дополнительно
- Data Scientist, Data Analyst, ML Engineer: а в чем разница?
- Сколько зарабатывает Data Scientist
- Востребованность профессии дата-сайентиста
- Тренды Data Science в 2025 году
- Как стать Data Scientist
- FAQ про Data Science
- Коротко о главном
Что такое Data Science
Data Science — это компьютерная наука о данных, основанная на машинном обучении, статистике, системном анализе и высшей математике. Что делать с зеттабайтами данных, как сделать их полезными для людей и бизнеса, как использовать для решения ежедневных проблем в самых разнообразных отраслях экономики (от медицины до IT) — все эти вопросы и являются областью изучения науки о данных. Также это процесс извлечения полезной информации из огромных объемов зашумленных данных.
Простыми словами, Data Science — это наука о данных, позволяющая выводить закономерности в любых отраслях науки, бизнеса, медицины и других сферах жизни.

Специалисты по данным чаще всего полагаются на искусственный интеллект и машинное обучение.
Примеры отраслей дата-саенс:
- Статистика. Изучение статистики в любых аспектах и проблемах.
- Анализ данных. Обработка raw-данных с целью придания им необходимого вида, например, для подтверждения или опровержения гипотез.
- ИИ (искусственный интеллект). Обучение алгоритмов на реальных данных.
Как Data Science преобразует наше восприятие реальности?

Зачем и какому бизнесу нужна Data Science
Когда бизнесу нужно задействовать науку о данных? Типичный кандидат на найм дата-сайентиста — крупный бизнес, у которого:
- Накопилось огромное количество данных и есть желание их использовать. Беспорядочные массы терабайт «сырых данных» бизнесу ни к чему. Ему нужны данные, которые подтвердят или опровергнут определенную теорию, помогут стимулировать инновации или увеличат эффективность текущих продуктов.
- Очень большой бюджет на эксперименты. Мало получить и подготовить данные, необходимо также их внедрить и перестроить работу бизнеса на основе новых теорий. Обработанные данные полезны только тогда, когда бизнес может позволить себе меняться.
- Компания относится к отраслям: ecommerce, финансы, спорт, здравоохранение, государственное управление, логистическая ниша, недвижимость, реклама, промышленность. Для этих сфер экономики уже существуют готовые модели машинного обучения.
Кто такой специалист Data Science
Наука о данных включает в себя несколько дисциплин для максимально целостного, точного и тщательного изучения любых необработанных типов данных.
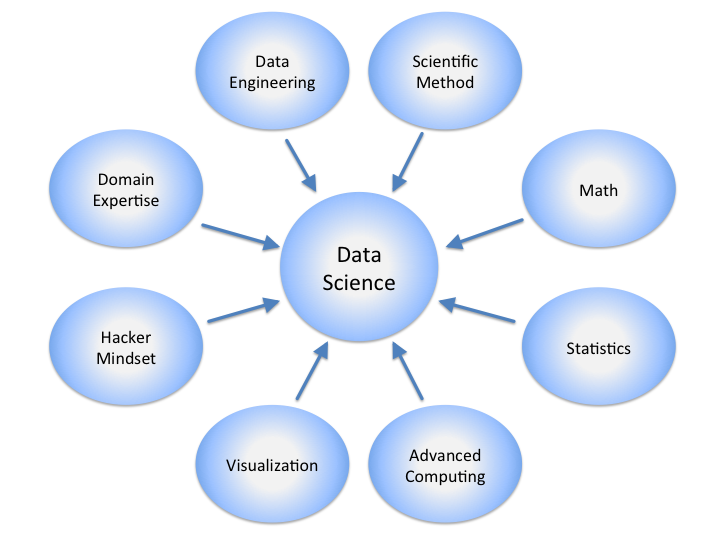
Дата-сайентист — это программист, который занимается сбором, организацией и анализом данных: устанавливает закономерности, проверяет конкретные теории. Некоторые специалисты по данным специализируются на узких областях анализа, другие являются универсальными программистами, обладая навыками, охватывающими все: от инженерии данных и математики, до статистики, передовых вычислений и визуализации.
.jpg)
Задача такого специалиста — не только собрать данные, но и корректно проанализировать их исходя из главной цели анализа. Типичный специалист по данным обладает превосходными познаниями в области математики и статистики, а также имеет широкий опыт использования нескольких языков программирования. К джентельменскому набору Data Science относится SQL, R и «Питон».

Не стоит путать дата-сайентиста с бизнес-сайентистом или бизнес-аналитиком. Эти специалисты работают только с коммерческими показателями бизнеса. Например, оценивают успешность продвижения в каждом конкретном канале, анализируют количество заявок за определенный период или проверяют другие коммерческие метрики бизнеса.
Также не стоит путать дата-сайентиста с дата-инженером. Дата-инженер только занимается физической добычей, сбором данных, настраивает выгрузку и объединяет данные из нескольких источников. Дата-сайентист — проверяет гипотезы, тестирует их в необходимых системах, создает алгоритмы.
Чем занимается специалист по Data Science
Прежде чем отвечать на этот вопрос, давайте рассмотрим науку о данных с точки зрения этапов ее жизненного цикла:
- Захват данных: сбор, ввод, прием и извлечение.
- Обслуживание и поддержка: хранение данных, их очистка и подготовка, а также обработка и создание классификации.
- Процесс: интеллектуальный анализ данных, кластеризация и классификация, моделирование данных и суммирование.
- Анализ данных: отчеты о данных, их визуализация, бизнес-аналитика и принятие решений.
- Коммуникация: исследовательский и подтверждающий анализ, прогнозный анализ, регрессия, анализ текста и качественный анализ.
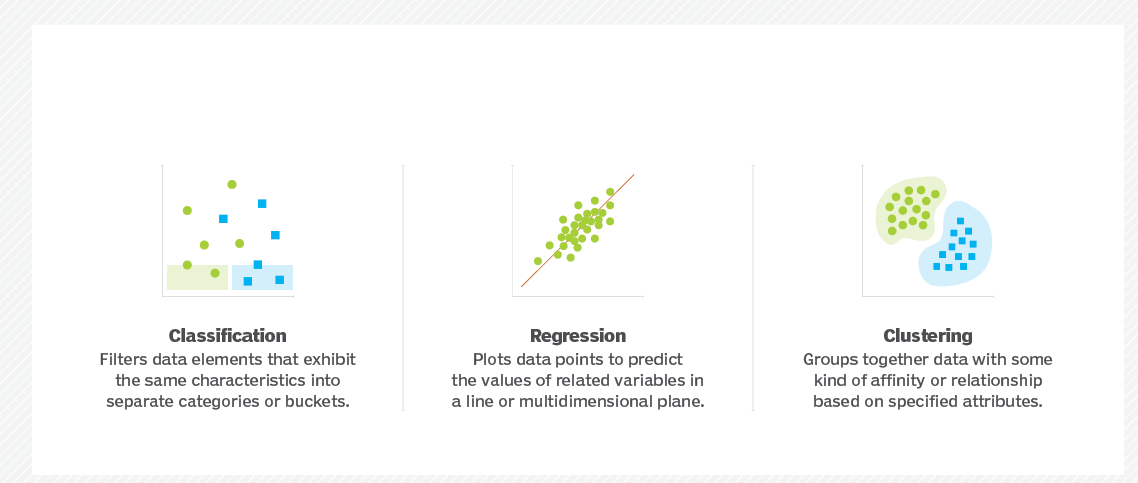
Если подытожить, дата-сайентист ищет закономерности в больших данных и формирует полезные модели, которые можно использовать практически — например, прогнозную. Алгоритмы всегда формируются на основе реальных пользовательских данных.
Модель DS может быть использована для прогнозов или предсказания определенного результата. Находя связи в данных и устанавливая закономерности, дата-сайентист может тестировать и внедрять сформированные им алгоритмы и модели машинного обучения.

Должностные обязанности специалиста по Data Science
Круг обязанностей специалиста по данным может отличаться от компании к компании. Например, в одном банке специалист может заниматься исключительно вопросами скоринга, в другом — только вопросами по конкретному банковскому продукту. Но чаще всего список таких обязанностей у специалиста примерно одинаковый.

Вот основные обязанности специалиста:
- Тщательный анализ ТЗ.
- Создание модели. Тестирование основной функциональности. Доработка модели при необходимости.
- Сопровождение созданной модели.
- Поэтапное внедрение созданной модели. Такое внедрение может касаться не только непосредственного продукта бизнеса, но и бизнес-процессов в широком смысле.
- Подготовка полученных от инженера данных.
- Разметка подготовленных данных.
- Анализ экономического эффекта в случае успешного и неуспешного внедрения алгоритма (модели).
- Создание и проработка ключевых показателей, по которым будет оцениваться эффективность созданной модели.
Перед тем, как начинать работу с данными, необходимо взвесить все за и против, ведь методом анализа и машинного обучения можно решить далеко не все задачи бизнеса.
Не нужно начинать работу, если проблема, которую нужно решить, заведомо проигрышная.
Карьерный путь в Data science: от Junior до Senior
Для удобства мы разделим каждый уровень по типичным задачам и нужным скиллам. Начнем с самого младшего специалиста.
Junior data scientist
- Типичные задачи. Сбор и очистка данных, разведочный анализ, базовые модели, подготовка признаков и, конечно, помощь в постановке A/B-тестов.
- Hard-скиллы. Python и SQL, pandas и NumPy, scikit-learn и основы статистики точно пригодятся в начале. Нужно знать Git (система контроля версий), потребуется умение визуализировать результаты.
- Soft-скиллы. Дисциплина! Далее — быстрая обучаемость, аккуратность, умение задавать уточняющие вопросы и формулировать простые выводы для бизнеса.
Middle data scientist
- Типичные задачи. Подготовка дизайна экспериментов, выбор и настройка моделей, продвинутая валидация, совместная работа с инженерами по данным. Также нужны навыки взаимодействия с ML-инженерами — над пайплайнами (конвейерами обработки данных).
- Hard-скиллы. XGBoost и LightGBM, сюда же — продвинутые схемы валидации. Точно нужен PyTorch на уровне прототипов, DVC и MLflow (трекеры экспериментов), а также основы MLOps.
- Soft-скиллы. Сильно нужна приоритизация, как и навык работ с неопределенностью. Из этого, частично, следует умение переводить бизнес-цели в метрики моделей. И обратно тоже.
Senior data scientist
- Типичные задачи. Совместная постановка задач с бизнес-заказчиком, архитектура решения целиком, управление рисками, менторство команды, ответственность за качество, стоимость и сроки. И это лишь самое необходимое.
- Hard-скиллы. Архитектура экспериментов, фреймворки продакшена, мониторинг данных, безопасность данных.
- Soft-скиллы. Лидерство, переговоры, навыки сторителлинга, умение защищать решения на языке денег и клиентской ценности.
Где искать заказы специалисту Data Science
Data Scientist редко работает как независимый специалист. Обычно он находится в составе компании и делает точные оценки и прогнозы по строгому техническому заданию бизнеса. Тем не менее, внештатные специалисты в этом профиле также существуют, но компании больше заинтересованы в работниках, которые находятся в штате.

Биржи фриланса
Искать заказы по Data Science можно на этих десяти биржах:
- Workzilla.
- Upwork.
- Weblancer.
- AngelList.
- Indeed.
- Freelancehunt.
- Freelancer.
- Freelance.ru.
- Kaggle.
- Peopleperhour.

Доски объявлений
Не сбрасывайте со счетов и традиционные доски объявлений — hh.ru, rabota.ru, superjob.ru. Крупные российские компании часто ищут специалистов именно через эти площадки.
Сайты profi.ru и YouDo
Используйте и сайты наподобие profi.ru (или YouDo). Зарегистрируйте профиль специалиста и укажите свою специализацию («Наука о данных»). На том же profi.ru, например, сейчас зарегистрировано более 4 000 программистов.
Telegram-каналы
Найти работу и заказы можно и в трех Telegram-каналах:
Ниже дам еще 18 каналов, в которых часто встречаются вакансии с самым разнообразным IT-профилем:
- Progjob
- Alenavladimirskaya
- Careerspace
- Solvery
- Myjobit
- Budujobs
- Jobforjunior
- ITlenta
- Jobskolkovo
- Remoteit
- Djinni_jobs_bot
- Forfrontend
- Seohr
- Theyseeku
- Distantsiya
- Antirabstvoru
- Remotejobss
- Yojob
Так выглядит типичный пост с вакансией на канале:
Если вы ищете вакансию в российской компании, попробуйте «Хабр Карьеру». Там очень часто публикуют предложения о найме для специалистов этого профиля.
Инструменты Data Science
Главным орудием современного специалиста по данным можно назвать язык программирования «Питон». Именно на этом языке осуществляется большинство этапов работы программиста по данным, включая анализ «сырых» данных, тестирование и эксперименты, написание кода, формирование моделей.
Что касается запросов к источникам, чаще всего они оформляются на SQL. В случаях, когда специалист по данным является еще и инженером машинного обучения, ему понадобится превосходное знание языка C++.

Язык R также используется в качестве основного. Чем он лучше «Питона»? В первую очередь, качественной визуализацией. Но Python имеет максимальный элементарный синтаксис и огромное количество готовых библиотек для работы с Big Data. Возможно, R чуть сложнее для новичка, поэтому среди начинающих он распространен несколько меньше, чем Python.
Ниже мы рассмотрим относительно полный список тех инструментов, которыми пользуются специалисты по данным на регулярной основе в 2025 году.
Контейнеризаторы приложений
Их будет полезно знать тем, кто планирует развиваться в продуктивизации ML и смежных направлениях и создавать Machine-Learning-платформы — мультимодели с несколькими версиями. Нужно обязательно знать контейнеризаторы приложений Docker и популярный сейчас Kubernetes.
.jpg)
Sandbox
Без интерактивного блокнота, где можно мгновенно визуализировать выполнение кода, — никуда. В качестве этого инструмента разумнее всего задействовать Jupyter Notebook — универсальный блокнот для выполнения ряда задач:
- Отладка любых разделов кода.
- Удобные аналитические сводки.
- Проверка и тестирование анализа данных. Эксперименты.
- Сложный разведочный анализ.
- Визуализация данных в диаграммах, гистограммах и графиках.
- Работа с классами и методами.
Работа с pipeline и его настройка
Термин «пайплайн», или конвейерная обработка, относится к методу разбиения последовательного процесса на подоперации, при этом каждая подоперация выполняется в выделенном сегменте, который работает одновременно со всеми другими сегментами. Здесь чаще всего используется Apache Airflow. В качестве альтернативы можно назвать фреймворк для «Питона» Luigi.
Machine Learning и создание ML-моделей
Рекомендуемые здесь библиотеки будут различаться в зависимости от тех потребностей, которые стоят перед разработчиком. Приведем библиотеки для самых распространенных сценариев машинного обучения:
- ИНС: Keras и TensorFlow.
- Одиночные модели: scikit-learn.
- Текст: NLTK.
- Классификация или несложная регрессия: LightGBM, XGBoost.
- Интерпретирование ML-модели: DiCE. В качестве полноценной замены можно рассматривать SHAP.
.jpg)
Среда разработки
Наилучший вариант PyCharm. Это интегрированная среда разработки с готовыми инструментами для анализирования кода, поддержкой Джанго, графическим отладчиком, и полноценными инструментами для организации и работы с юнит-тестами. Вот еще некоторые возможности, которые особенно пригодятся для дата-сайентиста:
- Комфортное написание Python-кода с реализацией любых модулей и классов.
- Отслеживание чистоты кода.
- Продуманное перепроектирование кода (рефакторинг).
- Умное форматирование текста.
- Настройка интерпретаторов.
- Полная поддержка распределенные системы управления версиями git.
Базы данных
Чем больше технологий хранения данных вы знаете, тем лучше. Минимальный набор: PostgreSQL, Oracle и конечно MySQL. В зависимости от особенностей проектов, может понадобиться знание Vertica и аналитической СУБД ClickHouse.
Точно не лишним будет умение работать с массово-параллельной СУБД Greenplum. Не стоит сбрасывать со счетов и апачевскую технологию Hadoop (особенно одноименную файловую систему HDFS), а также соответствующие фреймворки, утилиты и многочисленные библиотеки Hadoop. Все это понадобится при работе с данными. Чем больше будет ваш стек технологий, тем лучше и для самого специалиста, и для работодателя.
Облачные инструменты
Нужны навыки работы в облачных платформах Google (Google Drive, Google Cloud Platform, Google Colab) и Amazon (Redshift, AWS и конечно S3). Одними БД сегодня не обойтись и без знания облачных платформ дата-сайентисту делать нечего.

EDA и визуализация данных
Раз мы порекомендовали в качестве интерактивного блокнота JN, рассмотрим библиотеки именно для этой «песочницы». Три беспроигрышных варианта: Plotly, Matpotlib и питоновая библиотека Seaborn. Если вам этого мало, можно добавить в этот список scikit-learn.
Что нужно знать специалисту Data Science дополнительно
- Английский язык. С ним вы будете сталкиваться ежедневно. От коммуникаций с зарубежными коллегами до изучения справочных материалов и документов к программному обеспечению.
- Высшая математика. Без нее вообще никак. Все математические модели построены на определенных законах, которые описаны в математике. Только лишь математический анализ недостаточен. Как минимум, вам понадобится линейная алгебра, статистика, теории вероятности.
- Специфика проекта или отрасли. К этой особенности науки о данных нельзя подготовиться, ведь у каждого конкретного проекта существуют свои особенности. Например, domain knowledge (предметная область) в оценке рисков для страховой отрасли будет совершенно не похожа на предметную область логистической ниши. Решение этой проблемы заключается в постоянном самообучении, а также в коммуникации с экспертами в каждой конкретной отрасли.
- Языки программирования. Выше мы частично упоминали, что хорошим набором будет «Питон», R и SQL. Такой набор будет достаточным для джунов. Для мидлов и сеньоров в этот набор желательно включить хотя бы Java и языки группы С, например C++. Кроме того, изначально необходимо иметь хорошее представление о библиотеках для выбранного языка, которые будут использоваться для работы с большими данными. В первую очередь, речь о Matplotlib, Numpy, SciPy и конечно Scikit.
Data Scientist, Data Analyst, ML Engineer: а в чем разница?
- Data Scientist — специалист по науке о данных. Строит и проверяет модели под бизнес-цель.
- Data Analyst — аналитик данных. Отвечает за продуктовую аналитику, дашборды и эксперименты, фокус на SQL и BI-инструментах.
- ML Engineer — инженер по машинному обучению. Простыми словами, превращает прототипы в стабильные сервисы.
Для лучшего усвоения информации сделал сводную таблицу:
|
Роль |
Основная задача |
Инструменты |
Результат работы |
Требуемые навыки |
|
Data Scientist |
Прогнозы и рекомендации под KPI бизнеса |
Python, scikit-learn, XGBoost, SQL, PyTorch |
Рост метрик продукта, точности моделей |
Статистика, фичеинжиниринг, честная валидация, дизайн экспериментов |
|
Data Analyst |
Аналитика продукта, отчетность |
SQL, Excel, Power BI или Looker Studio |
Дашборды, инсайты для решений |
Продуктовая аналитика, визуализация, A/B-эксперименты |
|
ML Engineer |
Продакшен моделей |
Python, Docker, Kubernetes, Airflow, MLflow |
Надежный сервис, постоянный мониторинг качества |
MLOps, масштабирование, оптимизация затрат и задержек |
Сколько зарабатывает Data Scientist
В этом разделе я приведу статистику за сентябрь-октябрь 2025 года Моя оценка будет опираться большей частью на данные Habr Карьеры и тикеры вакансий на hh.ru, а также агрегатор Geeklink.
Начну с «Habr Карьеры». Средняя зарплата «ученого по данным» ≈211 666 ₽ в месяц. Добавим, что это расчет на основании около 600 анкет. Тренд 2025 года по отчету «Хабр Карьеры» — рост около двух процентов в первом полугодии.
Далее открываем Geeklink. Средняя зарплата Data Scientist по России на 1 октября 2025 года — ≈254 128 ₽, прирост около четырех процентов к сентябрю.
Переходим на рынок вакансий HeadHunter. Здесь я изучил выборку по Москве осенью 2025 года. Предложения для специалистов с опытом один-три года чаще встречаются в диапазоне 150-250 тысяч ₽. А вот позиции с опытом три-шесть лет доходят до ≈400 тыс. ₽ и выше в топ-отраслях.
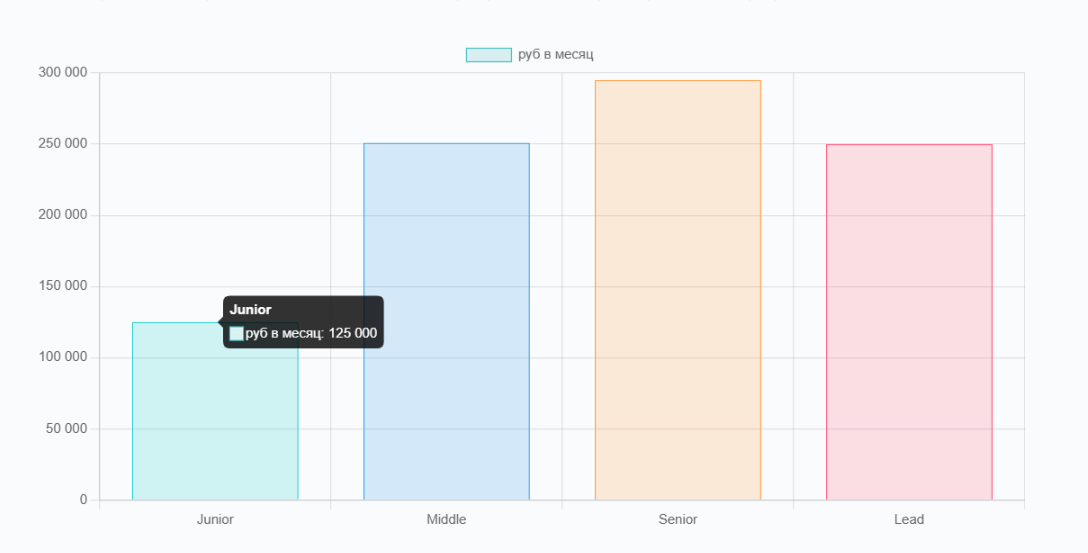
Резюмируем. Итоговая вилка зарплат по уровням специалиста по рынку РФ осенью 2025 будет следующей:
- Junior — около 100-160 тысяч ₽ в месяц, чаще через стажировки и работу на внутренних заказчиков.
- Middle — около 200-320 тысяч ₽, в Москве и Санкт-Петербурге чаще 230-330 тысяч ₽.
- Senior — 300-600 тысяч ₽ и выше — но только в финтехе, электронной коммерции и продуктах с активным использованием ИИ.
Востребованность профессии дата-сайентиста
По разным оценкам, в 2025 года в мире циркулирует более 175 зеттабайт данных. Это колоссальная цифра, которая свидетельствует о постоянном количественном росте информации о людях.
Ваш маршрут на работу, ваш последний поисковый запрос в «Яндексе» о ближайшей кофейне, ваш пост во «ВКонтакте» о том, что вы ели и даже данные с вашего фитнес-браслета тщательно анализируются компаниями и в дальнейшем используются для того, чтобы сделать вашу жизнь лучше и удобнее.
Только представьте: абсолютно любой ваш шаг в интернете тщательно отслеживается сотнями различных компаний!
Вот несколько фактов, которые позволяют судить о востребованности этой профессии:
- Специальность с самым высоким спросом по результатам ВЭФ.
- Более 400 вакансий на hh.ru.
- Более 350 вакансий на rabota.ru и superjob.ru.

Тренды Data Science в 2025 году
В глобальном смысле, находя связи и закономерности, наука о данных позволяет создавать новые продукты, предоставляет обществу революционные идеи и делает нашу жизнь более комфортной. Существует мало проблем, которые не поддаются решению через анализ данных. Таким образом, наука о данных может использоваться абсолютно для всего: от принятия важных бизнес-решений до аналитики или оценки рисков.
Проверка гипотез и установление самых эффективных вариантов — еще одна область, где наука о данных показывает себя наилучшим образом.
Далее рассмотрю семь трендов Data Science, которые станут особенно востребованными в 2025 году и далее.
1. Бум облачной миграции
Вскоре все больше бизнесов начнут готовиться к миграции приложений, помещая свои локальные приложения в контейнеры. Это будет связано с соображениями стоимости, нехваткой чипов и необходимостью масштабируемости. Компании перенесут свои онлайн-системы обработки транзакций, хранилища данных, веб-приложения, аналитику и ETL в облако.
Компании, у которых уже есть гибридные или мультиоблачные развертывания, сосредоточатся на переносе своей обработки данных и аналитики. Таким образом, они смогут переходить от одного поставщика облачных услуг к другому, не беспокоясь о периодах блокировки или использовании конкретных точечных решений.
2. Рост прогнозной аналитики
Предиктивная аналитика — это предсказание будущих тенденций и прогнозов с помощью статистических инструментов и методов, использующих прошлые и существующие данные. С помощью предиктивной аналитики организации могут принимать взвешенные бизнес-решения, которые помогут им развиваться. Ожидается, что к 2025 году мировой рынок прогнозной аналитики достигнет 21,5 миллиарда долларов США, а среднегодовой темп роста составит 24,5 %. Прогнозируемый невероятный рост связан с внедрением цифровой трансформации в ряде организаций. Сатья Наделла, генеральный директор Microsoft, заявила: «Мы увидели два года цифровой трансформации за два месяца».
3. Авто-ML
Автоматизированное машинное обучение или AutoML — одна из последних тенденций, которая способствует оптимизации рабочих процессов DS. Огромная часть работы специалиста по данным тратится на очистку и подготовку данных, и каждая из этих задач повторяется и требует много времени. AutoML обеспечивает автоматизацию этих задач и включает в себя построение моделей, создание алгоритмов и нейронных сетей не в полуавтоматических режимах.
4. TinyML
Это тип машинного обучения, который сжимает сети глубокого обучения, чтобы их можно было разместить на любом оборудовании. Универсальность, крошечный форм-фактор и экономичность — все это TinyML. Это одна из самых захватывающих тенденций в области науки о данных, с помощью которой можно создать ряд приложений. Встраивание искусственного интеллекта в небольшие устройства эффективно решает проблему недостатка мощности и пространства.
5. Лучшее регулирование данных
По данным G2, ежедневно создается 2 000 000 000 000 000 000 байт данных — это 18 нулей. Только представьте, какая колоссальная цифра! Оптимизация больших данных не может быть второстепенной задачей. С проникновением ИИ в такие отрасли, как здравоохранение, например, конфиденциальные данные пациентов не могут и не должны быть скомпрометированы. Да, утечки данных в компаниях — привычное дело. Но именно основные принципы конфиденциальности данных должны создать более безопасный подход к сбору и обработке ПДН. И машина будет выполнять эти задачи самостоятельно, нужно просто ее обучить.
6. ИИ как услуга (AIaaS)
Одна из самых больших проблем, связанных с AIaaS (искусственный интеллект как услуга), — соблюдение требований соответствия. Если ваш бизнес может выполнить свои нормативные требования и обязательства, AIAaS — отличный способ быстро и масштабно создавать решения на основе ИИ.
7. Сложность обучающих данных
Несмотря на все разговоры о том, что данные — это новая нефть и их невероятную важность для компаний / бизнеса, большая их часть остается неиспользованной. Зарубежные практики такие данные называют «темными»: они, в основном собираются, обрабатываются и хранятся только в целях соблюдения формальных требований.
К сожалению, это и одна из главных сложностей, которая препятствует применению контролируемого и неконтролируемого обучения. Есть определенные области, где большой репозиторий данных недоступен, и это может серьезно затруднить деятельность дата-сайентиста. Трансферное обучение, генеративно-состязательная сеть (GAN) и обучение с подкреплением решают проблему — уменьшают количество необходимых обучающих данных или генерируют достаточное количество данных, с помощью которых можно обучать модели.
Математика для Data Science — обширная тема. Мне близка мысль, что «Data Science — это математика для бизнеса».
Юрий Кашницкий — Staff GenAI Solutions Architect в Google Cloud
Как стать Data Scientist
В этом разделе я подготовил пошаговый план без лишней теории. Каждый шаг говорит, что именно делать, какую цель ставить и как понять, что вы готовы двигаться дальше. Примеры будут из маркетинга: конверсия, удержание, выручка.
Шаг 0. Подготовка среды за один вечер
Цель — чтобы у вас был рабочий стол для экспериментов.
Что сделать:
- Установите Python. Затем Jupyter Notebook (код и пояснения будут в одном месте). Подсказка: проще всего поставить дистрибутив Anaconda или Miniconda.
- Установите VS Code (удобный редактор кода).
- Создайте папку DS_учеба и файл план_обучения.md. Так будете записывать прогресс.
- Зарегистрируйтесь на GitHub (площадка для хранения кода и портфолио).
Проверьте готовность всей инфраструктуры. Для этого в Jupyter напишите и выполните 2 + 2, затем загрузите в GitHub первый файл с текстом «Начал учебу».
Приступаем к основному обучению.
Шаг 1. Знакомимся с основами математики и статистики — только то, что нужно для бизнеса
Цель — не углубляться в академическую математику. Нужно просто уверенно говорить на языке «данные и гипотезы».
Первая неделя. Среднее, разброс на своих данных
Что учить. Такие понятия как «среднее», «медиана», «минимум и максимум», «квартиль», «выбросы».
Практика. Возьмите Excel или Google Sheets. Загрузите таблицу заказов из реальной работы. Либо просто любой открытый датасет. Посчитайте средний чек, медиану. Затем вычислите разброс по неделям.
Результат. Один слайд «Портрет продаж за месяц» и короткий вывод.
Вторая неделя. Вероятность простым языком
Что учить. Вероятность как «шанс события», независимость событий, больше внимания уделяем риску ошибки.
Практика. По истории покупок прикиньте «шанс повторной покупки» для клиента, который купил один раз, и для клиента, который купил три раза.
Результат. Таблица с оценками вероятностей и два-три вывода словами.
Третья неделя. Проверка гипотез и А/Б тест
Что учить. Такие понятия как «гипотеза», «контрольная и тестовая группа», «ошибка первого и второго рода», «p-value» (число, показывающее, насколько результат случайный).
Практика. Придумайте гипотезу «новая кнопка увеличит конверсию». Смоделируйте в Excel две колонки с числами «до» и «после», посчитайте разницу и сделайте простой вывод: «разница могла возникнуть случайно или нет».
Результат. Одна страница «Гипотеза и вывод для менеджера».
Четвертая неделя. Минимум линейной алгебры для работы с таблицами
Что учить. Вектор и матрицу. Думайте, зачем вообще масштабировать признаки. И, почему «много признаков» — не всегда хорошо.
Практика. В Jupyter с библиотекой NumPy измените масштаб числовых столбцов. Посмотрите, как меняется график.
Результат. Скрины «до» и «после». Добавьте оба изображения в документ. По каждому напишите краткий комментарий.
Прежде чем переходить к следующему шагу, убедитесь в том, что вы умеете:
- Формулировать гипотезу.
- Собирать простую статистику.
- Ясно записывать выводы для менеджера.
Если ответы положительные на все три утверждения, можно идти дальше.
Шаг 2. Учим программирование для анализа — изучаем Python и SQL
Цель — свободно «тасовать» таблицы, чистить данные, строить графики.
Первая неделя. Основы Python
Что учить. переменные, списки, словари, условия, циклы, функции.
Практика. Посчитайте средний чек и выручку по неделям на сырых данных в CSV.
Результат. Раздел в тетради «Базовые расчеты для маркетолога». Скидывайте туда все идеи.
Вторая неделя. Библиотеки для данных
Что учить. Pandas (работа с таблицами), NumPy (числовые расчеты), Matplotlib и Plotly (графики).
Практика. Загрузите таблицу заказов, почистите пропуски, постройте графики: «выручка по неделям», «распределение среднего чека».
Результат. Два-три аккуратных графика с подписями и тезисный вывод.
Третья неделя. SQL — язык запросов к базам данных
Что учить. SELECT, WHERE, ORDER BY, GROUP BY, JOIN (соединение таблиц).
Практика. Установите SQLite (простая база на вашем компьютере), создайте две таблицы «клиенты» и «заказы», выполните пять запросов:
- Топ категорий по выручке.
- Клиенты без повторной покупки.
- Средний чек по каналам трафика.
- Конверсия по неделям.
- «Длинный хвост» товаров.
Результат. Файл с пятью запросами и скриншоты результатов.
Четвертая неделя. Мини-проект «Отчет маркетинга»
Что сделать. Собрать данные, очистить, визуализировать, написать краткие рекомендации для менеджера по продукту.
Результат. Файл и добавьте в него все нужные данные. Также создайте PDF на одну страницу с пояснениями — «Что делать бизнесу в следующем месяце». Загрузите все на GitHub.
Если вы уже уверенно читаете таблицы, пишете простые запросы, умеете строить графики без шпаргалок, переходим к третьему этапу обучения.
Шаг 3. Постигаем машинное обучение
Цель. Вам сейчас важно понять, как «машина учится на примерах», и также собрать свой первый предсказатель.
Первая неделя. Первая модель на реальной задаче
Что учить. Постановка задачи, разделение на обучение и проверку, метрика качества.
Практика. Ваша задача — сделать «прогноз выручки на следующую неделю». То есть — «уйдет клиент или останется». В scikit-learn (наборе готовых алгоритмов) соберите линейную регрессию или логистическую.
Результат. Сравнение «наивного прогноза» и модели с одним выводом. Ответьте, «что улучшилось и на сколько».
Вторая неделя. Деревья решений. Градиентный бустинг
Что учить. Деревья решений, соответственно, а также ансамбли Gradient Boosting (семейство алгоритмов для табличных данных).
Практика. На этом этапе обучите XGBoost или LightGBM на той же задаче, сравните с прошлой неделей.
Результат. Таблица «метрика до и после» и список из трех самых важных признаков.
Третья неделя. Тексты
Что учить. Изучайте концепцию представления текста как чисел! Почитайте про TF-IDF (вес слов в документе). И параллельно думайте про базовую модель — для тональности отзыва, например.
Практика. Соберите отзывы, отметьте вручную десять положительных и десять отрицательных, обучите простую модель.
Результат. Демонстрация, как модель классифицирует пять новых отзывов.
Четвертая неделя. Правильная оценка качества
Что учить. Понятия «кросс-валидации» (повторная проверка на разных разбиениях), Accuracy (доля верных ответов), ROC-AUC (качество ранжирования), RMSE (средняя ошибка).
Практика. Теперь посчитайте две метрики и объясните словами, какая понятнее вашему бизнесу.
Результат. Одна страница в стиле «Как мы измеряем успех модели и почему».
Проверка готовности. Сформулируйте конкретную задачу. Нужно собрать простую модель, посчитать метрику и объяснить результат «на языке денег» и «что делаем дальше».
Шаг 4. Работаем на практику. Портфолио
Цель. А вот теперь уже нужно показать работодателю, что вы решаете реальные задачи.
- Соберите три проекта с бизнес-ценой. например:
- прогноз оттока клиентов для подписочного сервиса;
- рекомендации товаров для интернет-магазина;
- прогноз спроса для платного трафика.
- Для каждого проекта напишите такие сущности как «проблема», «данные», «шаги решения», «метрики», «деньги» или «экономия времени».
- Оформите один проект как мини-сервис. Самый простой путь — нарисовать в графическом редакторе. С понятными кнопками, с инструкцией. Альтернатива — сделать форму в Streamlit (инструмент для простых веб-приложений на Python). Важно: нужно чтобы коллега смог легко повторить ваши шаги.
- Участвуйте в Kaggle (это соревнования по анализу данных). Пройдите хотя бы одно соревнование в команде. Очень поможет в плане тренировки аккуратности, валидации, а также умения работать по дедлайнам.
- Ищите стажировку активнее: можно несложный волонтерский кейс. Помогите некоммерческой организации или маленькому бизнесу: соберите отчет по данным, предложите простую модель. А затем посчитайте экономический эффект.
- В финале соберите портфолио. На GitHub сделайте репозиторий «portfolio», в корне — файл README с фотографией и ссылками на проекты. На одну страницу опишите каждый кейс и не забудьте приложить графики.
Готовность номер один сейчас должна быть такая: у вас есть три проекта, один из них показан как работающий прототип, есть понятный README (текстовый файл, который распространяется вместе с программным обеспечением и содержит информацию о нём) и есть выводы в терминах бизнеса.
Сколько времени займет обучение
При занятиях один-полтора часа в день, как правило, до первой стажировки — от 3 до 6 месяцев. Но, конечно, все индивидуально.
Помните правило «триста маленьких шагов»? Каждый день одна мини-задача, один график или одна функция.
Каждую субботу — ревизия:, что получилось, что мешало, какие выводы по данным и какие вопросы задать наставнику или сообществу.
Чек-лист готовности к первому собеседованию
Убедитесь, что на каждое утверждения на данном этапе вы способны дать положительный ответ:
- Я умею ставить гипотезу, проверять ее простым А/Б тестом. Могу объяснить, что такое p-value простыми словами.
- Я свободно читаю таблицы в pandas. Легко пишу базовые запросы SQL.
- Я обучил две модели на реальной задаче. Сразу объяснил результат менеджеру.
- У меня есть три оформленных проекта на GitHub. И короткое резюме с ссылками.
Pet-проекты — благо. Запереться и пройти всю Coursera — недальновидный план: вам не будет не хватать командной работы.
Юрий Кашницкий — Staff GenAI Solutions Architect в Google Cloud
FAQ про Data Science
Работа в этой специальности не так очевидна, как может показаться на первый взгляд. Даже изучив статью, вы наверняка это заметили. Чтобы решить типичные проблемы, я подготовил ответы на самые насущные вопросы новичков.
Можно ли стать дата-сайентистом без высшего образования?
Да. Важно само портфолио, важна математика и статистика на прикладном уровне. Важен Python в связке с SQL и опыт решения задач. Диплом помогает, но не обязателен.
Сколько времени занимает обучение?
При интенсивной траектории — 6-12 месяцев до первого джуна. До уровня middle — еще 1-2 года практики.
Нужно ли «много высшей математики»?
Глубокая математика нужна не всегда, но базис (линейная алгебра, вероятность, статпроверки) — обязателен для понимания моделей и самих этих A/B-тестов.
Kaggle обязателен?
Нет, но это быстрый способ прокачать валидацию, эксперименты и «хаки» (adversarial validation, GroupKFold и пр.).
Чем отличается работа в стартапе и энтерпрайзе?
В стартапе — шире зона ответственности (от сбора данных до деплоя), в корпорации — глубже специализация. В еще там вас ждут строгие MLOps-процессы.
Коротко о главном
- Data Scientist — специалист по науке о данных. Он помогает принимать решения: прогноз спроса, персональные рекомендации, скоринг риска и вклад в выручку.
- База профессии сейчас — это математика и статистика. Очень пригодится Python и SQL (язык запросов к базам данных), понимание бизнес-метрик.
- Эксперименты и валидация важнее «экзотических моделей». Так что сначала проверяем гипотезу и прирост ценности, а лишь затем усложняем.
- Портфолио, ваши практические кейсы — лучший пропуск на рынок. Одного «пройденного курса» обычно мало.
- Всегда «говорим на языке бизнеса»! А именно — считаем, сколько денег приносит модель и на каких условиях.

.png)

.png)
.png)

Комментарии
Комментариев пока нет. Будьте первым!
Оставить комментарий