

Один из самых больших мифов в SEO — страшное наказание за дублированный контент. Никакого ручного штрафа за дубли страниц не существует. Google Search Console никогда не отправит уведомление об ошибке с текстом о пессимизации за копии.
Но это не значит, что веб-страница не пострадает. Дублирования контента съедают краулинговый бюджет, размывают ссылочный профиль и вызывают каннибализацию. Когда поисковая система видит идентичный материал по разным URL-адресам, алгоритм сам решает, какой вариант релевантный. Часто выбор оказывается ошибочным, из-за чего падает трафик и снижается позиция в выдаче.
- План устранения дублей за 15–30 минут
- Что такое дублированный контент
- К чему приводит дублирование контента на сайте
- Откуда берутся дубли страниц
- Мониторинг дублированного контента
- Как управлять дублирующимся контентом: 301, canonical, noindex, robots
- Сравнение методов управления дублями
- Что делать с дублированным контентом
- Профилактика: как избежать появления дублей
- Контроль результатов после устранения дублей
- FAQ по дублированному контенту
План устранения дублей за 15–30 минут
Если нет времени на полный аудит, выполните базовую последовательность действий. Она закрывает большинство проблем с дублированием контента на сайте.
- Настройте 301-редиректы для зеркал: склейте версии http и https, www и без него, адреса со слешем и без.
- Используйте тег canonical для фильтров: страница вида
/catalog?sort=priceдолжна содержать ссылку на основной раздел. - Закройте служебный контент через noindex: страница для печати или результаты поиска по сайту не должны попадать в индекс.
- Проверьте отчеты в GSC: найдите ошибки сканирования и статусы дубликатов страниц.
- Скорректируйте внутренний ссылочный вес: направляйте линки только на канонический адрес.
- Проведите повторную проверку: через месяц оцените результат устранения проблемы.
Если не устранить техническую причину возникновения дубля, проблема обязательно вернется при следующем сканировании.

Что такое дублированный контент
Дублированный контент — полностью или частично совпадающее содержимое, доступное по разным URL. Не стоит путать копии с шаблонными элементами. Сквозной футер, навигация или сайдбар не вредят продвижению. Поисковый робот умеет отличать структуру сайта от основного текста.
Выделяют два типа проблемы. Полный дубль — стопроцентное совпадение кода и текста. Возникает из-за параметров, UTM-меток или несклеенных доменов. Частичный дубль — пересечение фрагментов текста. Например, одинаковое описание для разных товаров в интернет-магазине.
Многие вебмастера ищут копии только на старте разработки. Это техническая ошибка. Контент может дублироваться со временем: конкуренты парсят статьи из блога, контент-менеджеры копируют абзацы. Регулярная проверка обязательна.
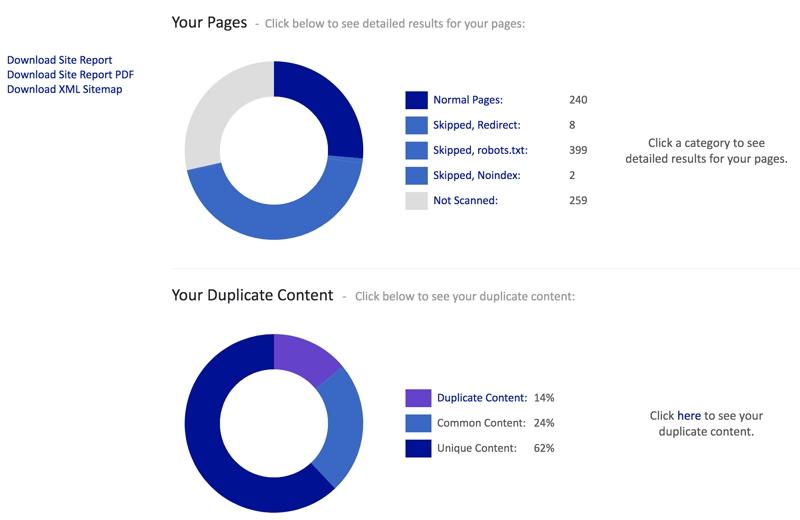
К чему приводит дублирование контента на сайте
Последствия всегда отражаются на метриках. Выделяют три причины, по которым дублирование негативно влияет на продвижение ресурса.
Потеря краулингового бюджета. Робот тратит лимиты на обход мусорных адресов. Важный новый материал индексируется неделями. Настройка редиректов высвобождает ресурсы краулера.
Каннибализация запросов. Несколько страниц с одинаковыми текстами конкурируют за один ключевой запрос. Поисковая система постоянно меняет релевантный URL в выдаче, из-за чего рейтинг обеих страниц падает.
Размывание ссылочного профиля. Внешние ссылки ведут на разные версии документа. PageRank дробится. Правильный редирект передает вес на нужный адрес.
Откуда берутся дубли страниц
Частый источник проблемы — особенности работы CMS. Система автоматически генерирует адреса. Разберем основные уязвимости.
| Причина | Пример URL | Риск | Решение |
|---|---|---|---|
| Зеркала домена | http://site.ru и https://www.site.ru | Высокий — дробится ссылочный вес | 301-редирект на основное зеркало |
| Конечный слеш | /catalog/ и /catalog | Средний — дубль страницы | 301-редирект к единому формату |
| Параметры и фильтры | /catalog?sort=price&color=red | Высокий — лавина дублей в каталоге | rel=canonical на базовый URL; Disallow в robots.txt |
| UTM-метки | /page?utm_source=yandex | Средний — дубли с рекламных кампаний | canonical на чистый URL или Clean-param |
| Пагинация страницы | /catalog/page/2/ | Средний — конкурирует с основной страницей | Self-canonical на каждой странице пагинации |
| Версии для печати / AMP | /page?print=1, m.site.ru/page | Средний — дополнительные версии в индексе | noindex на служебных версиях; canonical на AMP |
| CMS-архивы и теги | /tag/seo/, /archive/2024/ | Низкий — тонкий контент | noindex или canonical на основной раздел |
| Внутренний поиск | /search?q=кресло | Высокий — бесчисленные URL | Disallow /search/ в robots.txt |
Интернет-магазины страдают сильнее всего. Фильтры категорий генерируют сотни URL-адресов с идентичным контентом. Анализ веб-страниц для e-commerce — обязательная регулярная процедура.
Мониторинг дублированного контента
Для поиска дубликатов страниц используют специализированные сервисы. Комбинируйте инструменты для получения точного результата.
%201.png)
%201.png)
%201.png)
%201.png)
%201.png)
В Semrush доступен анализ на уровне домена. Программа сканирует ресурс и показывает общую долю неуникальных текстов.
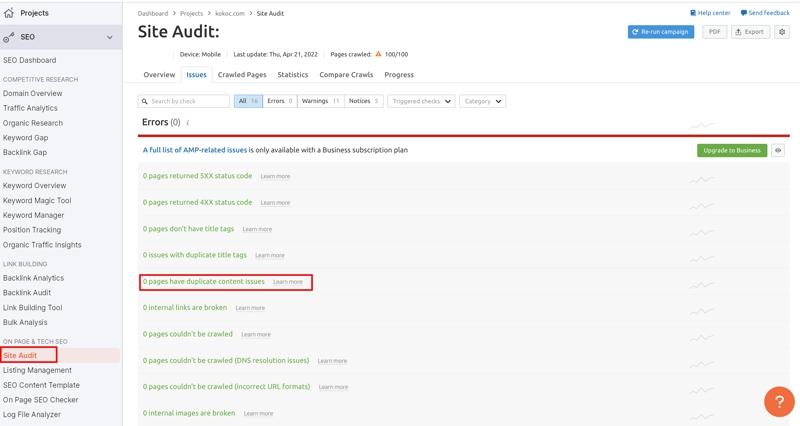
Siteliner помогает найти внутренние пересечения. Для каждой страницы формируется отдельный отчет с подсчетом процента совпадений.
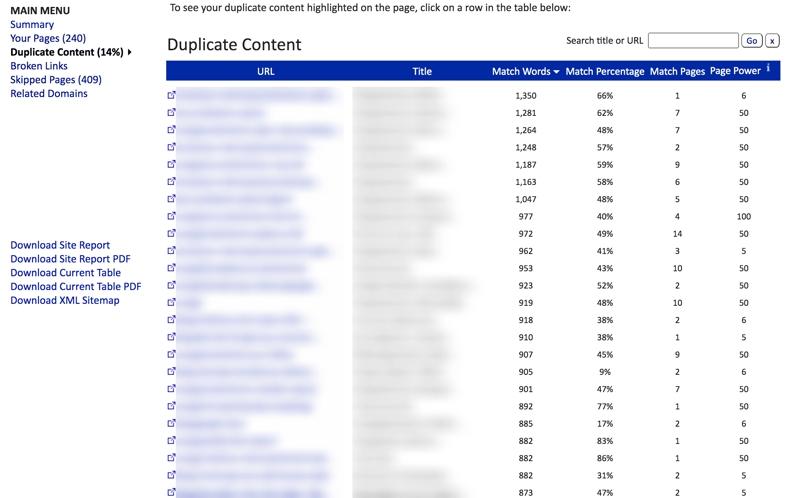
Duplichecker проверяет конкретный текст, но имеет ограничение в 1 000 слов для бесплатной версии. Подходит для точечного анализа.
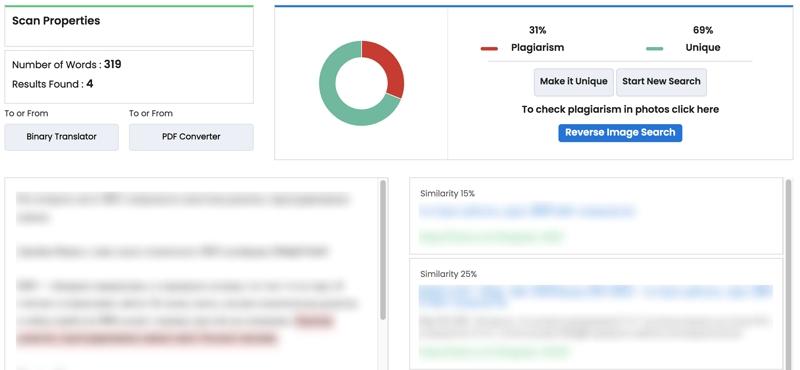
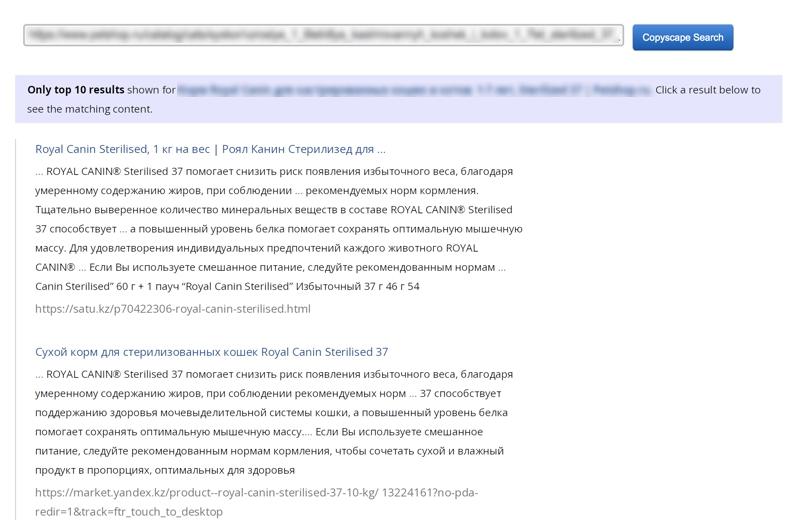
Copyscape ищет внешний плагиат. Достаточно указать URL-адрес. В бесплатной версии инструмент показывает до 10 сайтов с похожим содержимым.
Среди профессиональных платных решений выделяют:
- Copyleaks: глубокий анализ на базе ИИ.
- Screaming Frog: отлично ищет технический мусор и near-duplicate страницы внутри структуры.
- Sitechecker: комплексный аудит ресурса.
Как найти дубли через GSC и «Яндекс Вебмастер»
Панели для вебмастеров — базовый метод диагностики. Откройте Google Search Console, раздел индексирования. Ищите два ключевых статуса.
Первый — «Дубликат без указанного канонического URL». Google обнаружил похожие страницы, но вы не указали главную. Поисковая система выбирает сам.
Второй — «Альтернативная страница с правильным каноническим тегом». Страница исключена из индекса в пользу канонической. Это нормальное состояние при корректной настройке.
В «Яндекс Вебмастере» перейдите во вкладку «Индексирование» → «Страницы в поиске» → «Исключенные страницы». Фильтр по статусу «Дубль» покажет проблемные URL.
Поисковые операторы также полезны. Команда site:example.com покажет количество проиндексированных документов. Введите фрагмент текста в кавычках, чтобы найти точные копии в выдаче.
Допустимое количество неуникального контента
Поисковые системы не устанавливают жестких рамок в процентах. Алгоритмы оценивают наличие добавленной ценности. Важно уникализировать заголовок title, метатег description и ключевой фрагмент текста.
Правильный подход: настройте canonical на дублирующиеся версии страниц и сосредоточьтесь на проработке смысловых блоков, которые отличают документ от похожих.
Как управлять дублирующимся контентом: 301, canonical, noindex, robots
Переписать все тексты вручную невозможно, особенно для e-commerce проектов с тысячами карточек. Технические методы решают проблему быстрее.
301-редирект: склейка зеркал и протоколов
Метод физически перенаправляет пользователя на нужный вариант. Применяется, когда существует несколько адресов для одной сущности: разные протоколы, наличие www, слеши на конце.
Настройка для Apache (.htaccess) — перевод на https без www:
RewriteCond %{HTTP_HOST} ^www\.(.*)$ [NC]
RewriteRule ^(.*)$ https://%1/$1 [R=301,L]
RewriteCond %{HTTPS} off
RewriteRule ^(.*)$ https://%{HTTP_HOST}/$1 [R=301,L]Удаление конечного слеша (.htaccess):
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} ^(.+)/$
RewriteRule ^(.+)/$ /$1 [R=301,L]Настройка для Nginx — склейка www на основной домен:
server {
if ($host = 'www.example.com') {
return 301 https://example.com$request_uri;
}
}Не создавайте цепочки редиректов. Каждый лишний шаг снижает скорость загрузки и теряет часть ссылочного веса.
rel=canonical: управление дублями параметров и фильтров
Атрибут link rel canonical — это подсказка для поисковой системы. Тег указывает оригинальный источник. Применяется для пагинации, сортировок и UTM-меток.
Пример для страницы с фильтром сортировки:
<!-- На /catalog?sort=price -->
<link rel="canonical" href="https://example.com/catalog" />Каждая страница пагинации должна содержать каноническую ссылку на саму себя. Указывать первую страницу каталога ошибочно — это ломает индексацию глубоких уровней.
Для UTM-меток указывайте чистый URL:
<!-- На /page?utm_source=yandex -->
<link rel="canonical" href="https://example.com/page" />noindex и Disallow: когда страница нужна пользователям, но не поиску
Метатег robots с директивой noindex запрещает добавление в индекс, но разрешает сканирование. Файл robots.txt с командой Disallow блокирует обход краулером. Комбинация этих методов позволяет скрыть служебный раздел.
%201.png)
Для AMP-версий добавьте canonical, указывающий на основную страницу:
<link rel="canonical" href="https://example.com/page" />Disallow экономит краулинговый бюджет. Используйте команду для внутреннего поиска и административных панелей. Для UTM-параметров в Яндексе эффективна директива Clean-param:
Clean-param: utm_source&utm_medium&utm_campaignhreflang: дубли для мультирегиональных сайтов
Атрибут hreflang сообщает о языковой версии. Он не заменяет канонизацию, а дополняет ее. Используйте hreflang, чтобы поисковая система показывала правильную версию нужной аудитории.
Сравнение методов управления дублями
Выбор метода зависит от технической задачи. Сводная таблица поможет принять решение.
| Метод | Суть работы | Когда применять | Передает PageRank | Риски |
|---|---|---|---|---|
| 301-редирект | Физически перенаправляет пользователя и робота | Зеркала, смена протокола, удаленные страницы | Да, до 99 % | Цепочки редиректов снижают вес |
| rel=canonical | Указывает предпочтительную версию страницы | Параметры, фильтры, UTM, пагинация | Да, передает сигналы на каноник | Поисковая система может проигнорировать подсказку |
| noindex | Исключает из индекса, но позволяет сканирование | Служебные страницы, личные кабинеты | Нет | Не экономит краулинговый бюджет |
| Disallow (robots.txt) | Закрывает страницы от сканирования | Тестовые домены, внутренний поиск | Нет | Не гарантирует исключение из индекса без noindex |
Что делать с дублированным контентом
Техническое устранение — первый шаг. Далее требуется работа с текстовым наполнением. Поисковые системы оценивают материалы по критериям E-E-A-T.
Переписывание текстов актуально для информационных статей и ключевых коммерческих разделов. Если в интернет-магазине представлены идентичные товары, техническая склейка предпочтительнее рерайта.
Идентифицируйте все страницы с дублированным контентом. Если ресурсы ограничены, начните с категорий: они определяют ранжирование всего каталога. Страницы категорий с уникальным описанием ранжируются стабильнее.
Профилактика: как избежать появления дублей
Разовая настройка не защитит от появления новых ошибок при обновлении CMS. Требуется системный подход.
- Внедрите самоссылающийся canonical: каждая веб-страница должна указывать на себя.
- Блокируйте поиск: результаты внутреннего поиска генерируют бесконечное количество мусорных URL.
- Контролируйте метки: используйте Clean-param или canonical для рекламного трафика.
- Настройте мобильные версии: AMP-страницы должны содержать ссылку на десктопный оригинал.
- Закройте тестовые зоны: staging-окружение блокируется через noindex и базовую авторизацию.
Контроль результатов после устранения дублей
Поисковой системе требуется время на переобход. Первые результаты появляются через несколько недель.
| Метрика | Где смотреть | Что должно измениться | Частота проверки |
|---|---|---|---|
| Статусы в «Покрытии» | GSC → Страницы | Снижение ошибок канонизации | Раз в 2–4 недели |
| Исключенные страницы | «Яндекс Вебмастер» | Снижение URL со статусом «Дубль» | Раз в 2–4 недели |
| Показы и клики | GSC → Эффективность | Рост показов целевых страниц | Раз в месяц |
| Органический трафик | Яндекс.Метрика / GA4 | Стабилизация трафика | Раз в месяц |
| Объем индекса | Оператор site:domain.ru | Снижение количества мусорных страниц | Раз в месяц |
Если через два месяца метрики не улучшились, проверьте корректность внедрения тегов. Используйте инструмент проверки URL в консоли вебмастера.
FAQ по дублированному контенту
Штрафует ли Google за дублированный контент?
Нет. Google не накладывает ручных санкций за дублирование. Поисковая система просто выбирает одну версию документа для ранжирования. Реальные последствия: потеря краулингового бюджета и каннибализация запросов. Это влияет на позиции, но не является штрафом.
Чем 301-редирект отличается от canonical?
301-редирект физически перенаправляет пользователя на другой URL. Старая страница перестает существовать. Canonical — это рекомендация поисковой системе. Старая страница остается доступной для посетителей. Используйте редирект для технических склеек, а каноникал — для фильтров.
Как правильно настроить canonical для страниц пагинации?
Каждая страница пагинации должна иметь canonical на саму себя. Не указывайте тег всех страниц серии на первую: это приводит к потере трафика из-за проблем с индексацией глубоких уровней.
Нужен ли hreflang, если у сайта есть региональные версии?
Да. Для мультирегиональных проектов hreflang сообщает поисковой системе о языковых версиях. Это не замена canonical. Оба атрибута решают разные задачи и должны работать совместно.
Как часто нужно проверять сайт на дубли?
Минимум раз в квартал. Для интернет-магазинов с активным каталогом — раз в месяц. Дополнительно проводите аудит после каждого крупного обновления CMS или запуска новых разделов.



.png)
.png)



Комментарии (9)
Оставить комментарий