

Поисковые системы ежедневно обрабатывают огромные массивы информации, но ее качество, форма подачи и достоверность сильно различаются. Это усложняет ранжирование и часто не оправдывает ожидания пользователей. Вспомните, как часто в топ-10 Google и «Яндекса» вы сталкивались с такими проблемами:
- десяток однотипных статей, переписанных с одного и того же ресурса;
- невозможность найти точный ответ по низкочастотному запросу;
- пустые карточки маркетплейсов без описания товаров;
- бессмысленные SEO-тексты или устаревший на 10 лет контент.
Поведенческие факторы (ПФ) становятся ключевым инструментом для формирования более качественной и удобной поисковой выдачи, где даже сайт среднего качества не сможет долго занимать высокие позиции без реальной пользы для посетителей. Разберем, как Google и «Яндекс» отслеживают поведение пользователей, чтобы улучшить поиск и приблизить момент, когда любую информацию можно будет найти по первой ссылке.
Обе поисковые системы уже сделали большой шаг в этом направлении, внедряя нейросетевые ответы прямо в выдаче. Пользователь получает решение своей задачи, даже не переходя на сайт, — все происходит в одной вкладке.
%201.png)
- Что такое поведенческие факторы ранжирования
- Как поисковые системы собирают информацию о поведенческих показателях
- Основные типы поведенческих факторов
- Какие поведенческие факторы учитывает «Яндекс»
- Какие поведенческие факторы учитывает Google
- Сравнение учета поведенческих факторов в «Яндексе» и Google
- Как провести анализ поведенческих факторов: сервисы и метрики
- Важные нюансы измерений и частые ошибки интерпретации
- Как улучшить поведенческие факторы
- Оптимизация сниппета и рост CTR: практическое руководство
- Чем опасна накрутка поведенческих факторов
- Часто задаваемые вопросы (FAQ)
- Коротко о главном
Что такое поведенческие факторы ранжирования
Поведенческие факторы — это комплекс метрик, которые поисковые системы используют для оценки взаимодействия пользователей с сайтом. Анализ этих данных помогает определить ценность ресурса, его соответствие ожиданиям аудитории и, как следствие, его позицию в поисковой выдаче.
В 2025 году поведенческие метрики продолжают влиять на ранжирование, но характер этого влияния в Google и «Яндексе» различается. Google учитывает пользовательские сигналы (клики, время на сайте, взаимодействие с контентом) косвенно — как часть комплексной оценки качества и опыта страницы (Page Experience, Core Web Vitals). «Яндекс» же исторически использует более прямые поведенческие модели: такие показатели, как возврат к выдаче, активность на странице и общая вовлеченность, напрямую влияют на динамический вес и позиции ресурса.
Важно понимать, что обе поисковые системы анализируют не единичные визиты, а устойчивые закономерности. Агрегированные данные показывают, насколько хорошо сайт удовлетворяет поисковые интенты. Чем качественнее взаимодействие пользователей с ресурсом, тем выше его шансы на рост в выдаче.
Хотя поведенческие факторы — не единственный критерий, их роль значима, поскольку они напрямую отражают удовлетворенность пользователей. Однако их влияние может варьироваться в зависимости от тематики, типа запроса и других SEO-параметров.
Google и «Яндекс» учитывают время и поведение пользователей на сайте, кликабельность сниппетов и рост отказов при переходе из поиска. Сайты, которые смогли заинтересовать посетителя и удовлетворить его цель, получают бонус в ранжировании и попадают на первую страницу выдачи. Такой подход повышает содержательную ценность ресурсов в SERP и очищает интернет от некачественных сайтов и накрученного SEO.
Как поисковые системы собирают информацию о поведенческих показателях
Google и «Яндекс» получают данные об активности пользователей через собственные сервисы. Информация собирается после принятия пользовательского соглашения при регистрации аккаунта или установке программ. У каждой поисковой системы для этого есть свой набор инструментов:
- «Яндекс». Данные поступают из «Яндекс Браузера», встроенных расширений и скриптов «Яндекс Метрики». Дополнительно используется информация из продуктов экосистемы: виртуального помощника «Алисы» или сервиса статистики «Яндекс Радар».
- Google. Для сбора данных используются cookie и история посещений из Google Chrome, скрипты Google Analytics, история поиска в YouTube, а также действия пользователей, авторизованных в аккаунте Google или использующих устройства на Android.
Данные, которые используют поисковые системы для анализа, обезличены — применяются IP-хэши, идентификаторы устройств и другие методы анонимизации, соответствующие требованиям политик конфиденциальности (например, Google Privacy Policy, Политика конфиденциальности Яндекса). Это позволяет улучшать поисковую выдачу без нарушения конфиденциальности пользователей. Кросс-устройственное отслеживание и профили поведения затрудняют попытки скрыть активность от алгоритмов.
Основные типы поведенческих факторов
ПФ делятся на две большие группы: внешние (поведение в поисковой выдаче) и внутренние (поведение на самом сайте).
Внешние поведенческие факторы
Отображают взаимодействие пользователя с поисковой выдачей до перехода на сайт.
- CTR сниппета — процент кликов по ссылке сайта в SERP. Высокий CTR сигнализирует о релевантности заголовка и описания запросу.
- Быстрый возврат в поиск (pogo-sticking) — если пользователь быстро возвращается к выдаче, это может указывать на несоответствие контента его ожиданиям.
- Позиция клика — учитывается, с какого места в SERP был переход (клики с верхних позиций ценятся выше).
- Прямые заходы — если пользователь попадает на сайт по брендовому запросу, это положительно интерпретируется поисковыми системами.
- Несколько точек входа — когда посетители попадают на сайт не только из поиска, но и проходят по ссылкам с внешних источников, соцсетей, рассылок или мессенджеров, это также положительный сигнал для поисковых систем.
Внутренние поведенческие факторы
Отражают активность пользователя на сайте после перехода.
- Время на сайте (Time on Site) — чем дольше пользователь остается, тем лучше (если контент полезен).
- Глубина просмотра — количество просмотренных страниц за сеанс. Глубокий просмотр говорит о вовлеченности.
- Процент отказов (Bounce Rate) — доля сеансов, когда пользователь ушел без действий. Высокий показатель может указывать на нерелевантность страницы поисковому запросу.
- Взаимодействие с элементами — клики по кнопкам, прокрутка страницы, использование меню и форм.
- Достижение целей (конверсии) — выполнение целевых действий (покупка, подписка, заявка и т. д.).
- Социальные сигналы — лайки, репосты, шеринг, упоминание бренда в соцсетях, участие в обсуждениях и так далее.
Для качественной оценки сайта поисковые системы анализируют обе группы ПФ — как внешние, так и внутренние.
%201.png)
%201.png)
%201.png)
%201.png)
%201.png)
Какие поведенческие факторы учитывает «Яндекс»
«Яндекс» начал активно отслеживать поведенческие факторы еще в 2011 году, а с выходом алгоритма «Королев» в 2017 году эти метрики стали одним из главных критериев ранжирования. Рассмотрим, на что поисковая система обращает внимание в первую очередь.
Возвращение к поиску
Быстрый возврат пользователя к поисковой выдаче негативно сказывается на ранжировании. Это прямой сигнал о том, что сайт не смог удовлетворить запрос, что может быть связано с низкой релевантностью контента, плохим юзабилити или отсутствием полезной информации.
Большое количество возвратов в поиск сильно ухудшает позиции ресурса. Косвенно оценить этот показатель можно через анализ процента отказов.
Активность виджетов и шеринга
Активное использование виджетов социальных сетей и мессенджеров на сайте может коррелировать с полезностью контента. При ранжировании может учитываться количество переходов с сайта в соцсети и общая дистрибуция контента. Однако это косвенный сигнал: социальная активность отражает вовлеченность и охват, но его прямое влияние на позиции требует осторожной трактовки.
Узнать, как часто пользователи делятся контентом, можно через отчет «Поделиться» в «Яндекс Метрике»:
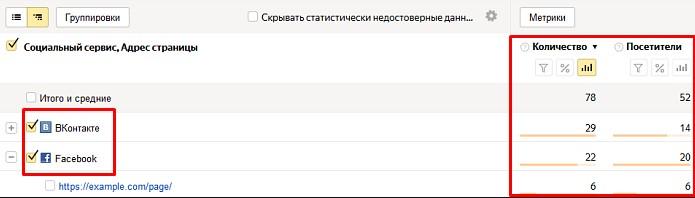
CTR сниппета и быстрых ссылок
Кликабельность сниппета свидетельствует о релевантности контента поисковому запросу. «Яндекс» также добавляет в сниппет быстрые ссылки, кликабельность которых отражает смысловую и практическую ценность ресурса.
Высокий CTR сниппета и быстрых ссылок говорит о пользе ресурса для аудитории на фоне конкурентов, что положительно влияет на ранжирование. Качественная проработка сниппетов позволяет значительно улучшить позиции в поиске.
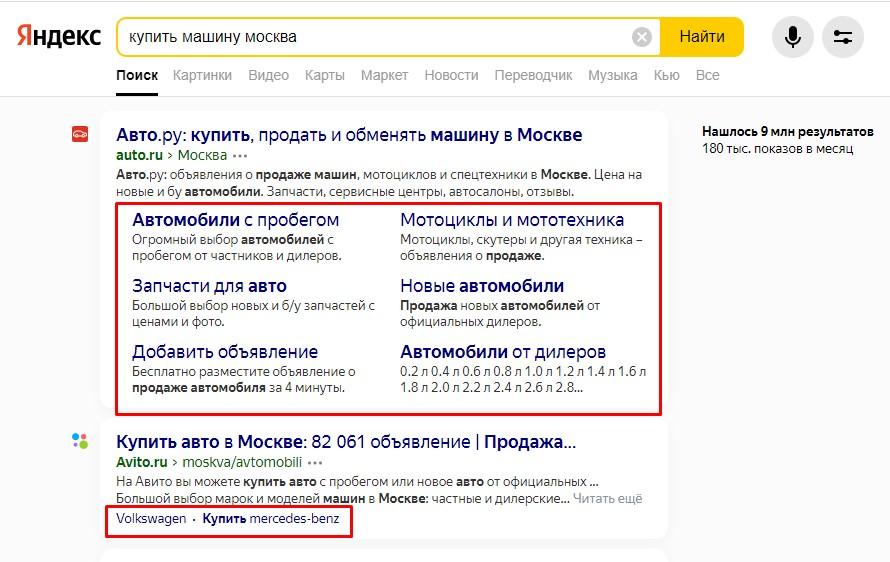
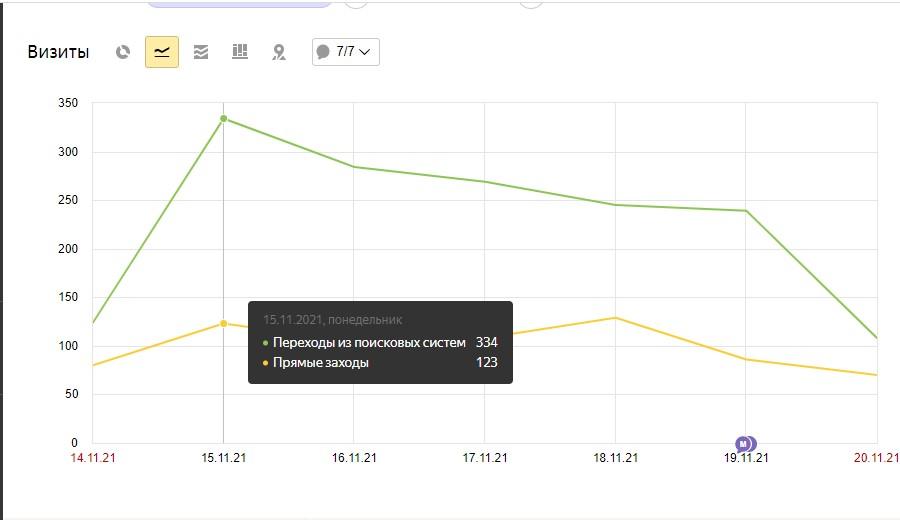
Прямые переходы на сайт
Прямые переходы свидетельствуют о наличии у ресурса постоянной аудитории, которая добавила сайт в закладки или вводит URL в адресную строку. Это говорит о практической ценности сайта: ресурсы, на которые пользователи регулярно возвращаются, получают преимущество в выдаче.
Показатель отказов
В «Яндекс.Метрике» этот показатель отражает процент визитов длительностью менее 15 секунд, в течение которых не было зафиксировано действий на странице. В Google Analytics (Universal Analytics) отказом считался просмотр только одной страницы. В GA4 этот подход изменился.
Высокий процент отказов в «Яндексе» свидетельствует об отсутствии практической ценности сайта для пользователя. Это может быть вызвано плохой оптимизацией, нерелевантной информацией или медленной загрузкой, из-за чего посетители сразу покидают ресурс.
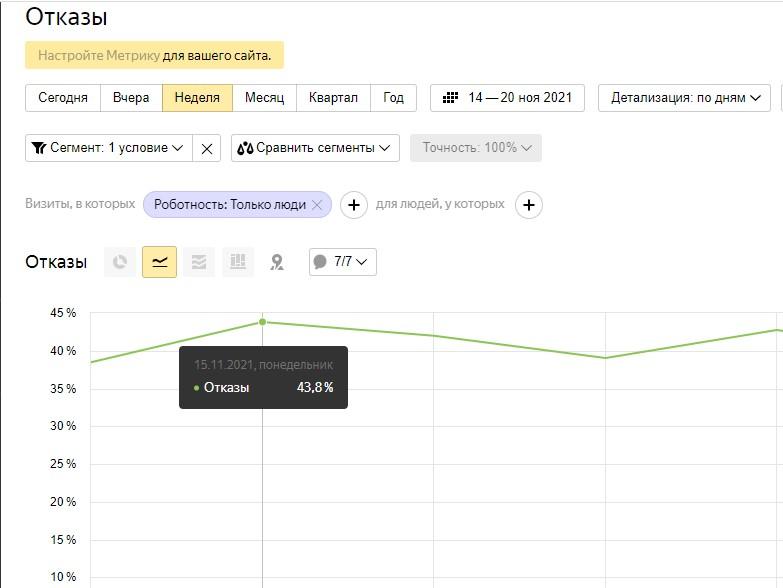
Допустимые значения отказов зависят от типа страницы и ниши. Для информационных сайтов показатель 40–50 % можно считать приемлемым, для e-commerce — лучше стремиться к 20–30 %. В Google Analytics 4 рекомендуется ориентироваться на Engagement Rate (показатель вовлеченности) и достижение целей страницы, а не на абсолютные значения отказов.
Активность и перемещение по сайту
Ключевое преимущество «Яндекс Метрики» — инструмент «Вебвизор», который позволяет отслеживать поведение каждого пользователя. Он записывает, что посетитель смотрел на сайте, как и когда скроллил страницу, где задерживал внимание.
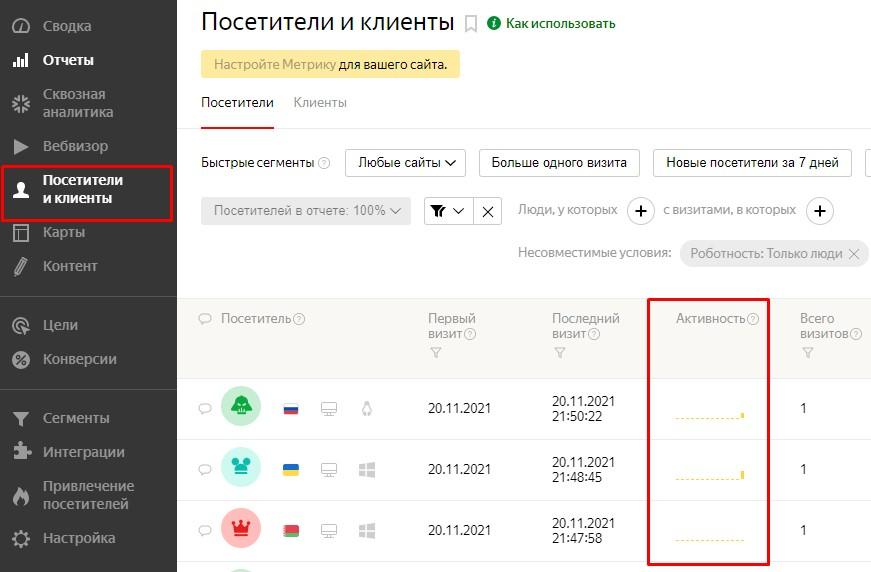
Отследить активность конкретного пользователя можно из его карточки, кликнув на иконку визита. Система запустит видеоролик с полной историей его действий на сайте.
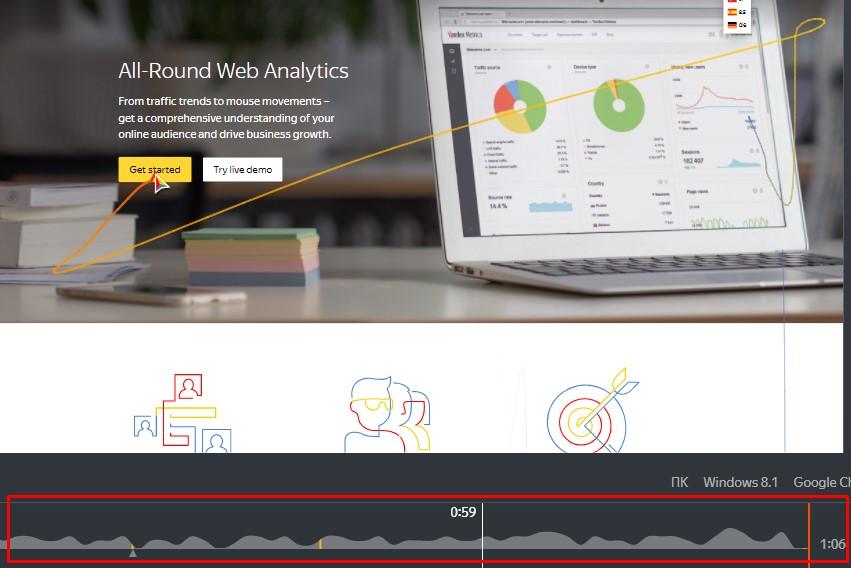
Данные о том, что делал и где останавливал внимание пользователь, используют и роботы «Яндекса» при анализе популярности страниц и расчете их динамического веса. Также отслеживание активности помогает поисковой системе бороться с накруткой поведенческих факторов.
Какие поведенческие факторы учитывает Google
В алгоритмах Google значимость поведенческих факторов менее выражена, чем у «Яндекса». Наибольшее влияние на ранжирование оказывает Page Experience — комплексный показатель опыта взаимодействия пользователя со страницей, который объединяет юзабилити, безопасность и скорость загрузки.
Core Web Vitals: скорость и стабильность
В 2025 году Google ориентируется на ключевые интернет-показатели (Core Web Vitals):
- LCP (Largest Contentful Paint) — скорость загрузки крупнейшего элемента контента. Хорошее значение — менее 2,5 секунд.
- INP (Interaction to Next Paint) — отзывчивость интерфейса (заменил FID в 2024 году). Хорошее значение — менее 200 миллисекунд.
- CLS (Cumulative Layout Shift) — визуальная стабильность страницы. Хорошее значение — менее 0,1.
Проверить эти метрики можно в PageSpeed Insights или Google Search Console (раздел «Основные интернет-показатели»).
Page Experience
Сюда входит комплексная оценка удобства страницы: мобильная адаптивность, безопасное соединение (HTTPS), отсутствие агрессивных межстраничных баннеров и навязчивой рекламы. Рекомендации Google доступны в официальном руководстве Page Experience Guide.
Удовлетворенность поиском (Searcher Satisfaction)
Google стремится показывать идеальный ответ на запрос. Низкий процент возвратов в поиск (pogo-sticking) — хороший сигнал. Если высокий CTR сочетается с долгим временем на сайте, значит, контент соответствует ожиданиям. Глубина просмотра и взаимодействия (скроллинг, клики по внутренним ссылкам) также важны.
Языковая и региональная релевантность
Google анализирует язык контента и геопривязку пользователя. Языковая модель BERT помогает понимать контекст запроса. Если пользователи из определенной страны чаще выбирают ваш сайт, он получит приоритет в локальной выдаче. Атрибуты hreflang помогают правильно ранжировать мультиязычные версии.
Косвенное влияние на ранжирование в Google оказывают поведенческие факторы в поиске, такие как кликабельность сниппетов и удовлетворенность результатами. Если пользователь зашел на сайт и решил свою задачу, ресурс получит бонус к ранжированию.
При этом посещаемость, показатель отказов и глубина просмотра не являются прямыми факторами ранжирования в Google, согласно официальной документации. Однако эти параметры стоит отслеживать в Google Analytics для оптимизации сайта и улучшения юзабилити. В первую очередь сайт должен быть удобен для целевой аудитории, а не для поисковых алгоритмов.
Сравнение учета поведенческих факторов в «Яндексе» и Google
Чтобы быстро понять различия в подходах двух поисковиков, смотрите таблицу:
| Параметр | «Яндекс» | |
|---|---|---|
| Степень влияния ПФ | Прямое влияние через поведенческие модели; динамический вес страниц | Косвенное влияние через системы качества и Page Experience |
| Ключевые метрики | Возврат в поиск, время на сайте, клики, вовлеченность (скролл, паузы) | CTR, удовлетворенность поиском, Core Web Vitals (LCP, INP, CLS) |
| Инструменты анализа | «Яндекс Метрика», «Вебвизор», «Вебмастер» | Google Analytics 4, Search Console, PageSpeed Insights |
| Скорость реакции | Быстрее реагирует на изменения паттернов поведения | Консервативнее; учитывает устойчивые закономерности |
| Санкции за накрутку | Пессимизация, фильтры; возможна потеря позиций на долгий срок | Ручные меры, фильтры качества; меньший акцент на детекцию накрутки ПФ |
Как провести анализ поведенческих факторов: сервисы и метрики
Для полноценного аудита поведения пользователей необходимо использовать несколько инструментов одновременно, так как каждый из них дает свой срез данных.
Google Analytics 4 (GA4)
Основной инструмент для анализа внутренних ПФ. Ключевые метрики:
- Engaged Sessions (Вовлеченные сеансы) — сеансы, которые длились более 10 секунд, включали событие-конверсию или содержали два и более просмотра страниц.
- Engagement Rate (Показатель вовлеченности) — процент вовлеченных сеансов. Формула: Engaged Sessions / Всего сеансов × 100 %.
- Average Engagement Time (Среднее время взаимодействия) — среднее время активного взаимодействия с контентом (прокрутка, клики, фокус на вкладке).
- События (Events) — отслеживание микровзаимодействий: scroll (прокрутка >90 %), click, form_submit, video_start.
- Когорты (Cohorts) — анализ удержания и возвратов пользователей по группам.
Для анализа SEO-трафика настройте сегментацию в отчете «Привлечение трафика» → «Источники» → фильтр «Группа каналов по умолчанию» → «Organic Search». Подробнее об отчетах — в справке GA4.
«Яндекс Метрика»
Предоставляет глубокую детализацию поведения на уровне отдельных визитов:
- Вебвизор — запись сеансов с визуализацией действий пользователя.
- Карта кликов — тепловая карта, показывающая самые кликабельные элементы.
- Карта скроллинга — визуализация глубины прокрутки.
- Отчеты: «Источники → Поисковые фразы» и «Содержание → Страницы входа».
Google Search Console (GSC)
Анализ внешних поведенческих факторов в выдаче:
- CTR по запросам — процент кликов на ваш сайт для конкретных ключевых фраз.
- Позиции — средняя позиция сайта для каждого запроса.
- Сегментация по устройствам, странам и страницам.
Отчет «Эффективность» в GSC позволяет быстро выявить страницы с низким CTR для доработки сниппетов.
«Яндекс Вебмастер»
Аналог GSC для «Яндекса»:
- Кликабельность сниппетов — процент кликов по вашим ссылкам в выдаче.
- Быстрые ссылки — анализ эффективности дополнительных ссылок.
- Диагностика сниппетов — проверка корректности отображения Title, Description, микроразметки.
Тепловые карты и инструменты записи сеансов
Дополнительно можно использовать сторонние сервисы: Hotjar, Crazy Egg или бесплатный Microsoft Clarity. Они дают визуализацию поведения пользователей: зоны внимания, клики, движения мыши.
Важные нюансы измерений и частые ошибки интерпретации
Анализ поведенческих факторов требует внимательного отношения к методологии. Ошибки в интерпретации данных могут привести к неверным выводам и бесполезной оптимизации.
| Ошибка | Как проявляется | Что делать |
|---|---|---|
| Путаница Bounce Rate в GA4 и UA | В Universal Analytics отказ — просмотр одной страницы. В GA4 — отсутствие вовлеченности (сеанс <10 с, без событий, <2 просмотров). | Ориентируйтесь на Engagement Rate (100 % − Bounce Rate в GA4). Настройте события для фиксации микровзаимодействий. |
| Искажение данных из-за AdBlock | До 20–30 % пользователей блокируют скрипты аналитики; реальный трафик выше зафиксированного. | Используйте серверную аналитику (server-side tracking) или сравнивайте данные с логами сервера. |
| Проблемы атрибуции | Модель «Последний клик» отдает всю ценность конверсии последнему каналу, игнорируя вклад остальных. | Применяйте модели Data-Driven Attribution в GA4 или линейную атрибуцию для полной картины. |
| Некорректный учет переходов в SPA/PWA | В одностраничных приложениях переходы внутри сайта не засчитываются как отдельные просмотры страниц. | Настройте отслеживание виртуальных просмотров страниц (virtual pageviews) через Google Tag Manager. |
| Высокий Engagement Rate, но низкие конверсии | Пользователи долго находятся на сайте, но не совершают целевых действий. | Проверьте релевантность контента запросу, четкость CTA и наличие технических проблем (неработающие формы, медленная загрузка). |
| A/B-тесты без статистической значимости | Выводы сделаны на малой выборке или за короткий период, что делает результаты ненадежными. | Используйте калькуляторы статзначимости; собирайте данные минимум 2–4 недели на достаточном объеме трафика. |
%201.png)
Как улучшить поведенческие факторы
Работа ведется в нескольких направлениях.
Оптимизация для SERP (внешние поведенческие факторы)
Начните с оптимизации сниппета. Привлекательный заголовок (Title) и описание (Description) повышают кликабельность (CTR). Заголовок должен быть длиной 50–60 символов, содержать основной ключ и привлекать внимание. Описание (120–160 символов) должно четко объяснять пользу страницы и включать призыв к действию.
Используйте микроразметку Schema.org. Она помогает поисковикам лучше понять контент и может дать расширенные сниппеты (рейтинги, FAQ). Для статей актуальны типы Article и FAQPage. Проверить разметку можно через Google Rich Results Test.
Улучшение контента (внутренние поведенческие факторы)
Контент должен максимально полно отвечать на запрос пользователя. Глубоко раскрывайте тему, используйте связанные термины (LSI-слова) и приводите конкретные примеры. Структурируйте текст: используйте подзаголовки H2-H3, короткие абзацы и списки. Визуальный контент (изображения, инфографика, видео) увеличивает время на странице. Оптимизируйте изображения (формат WebP, сжатие) и добавляйте описательные Alt-теги.
Юзабилити и дизайн сайта
Медленные страницы увеличивают процент отказов. Оптимизируйте скорость загрузки с помощью инструментов вроде PageSpeed Insights. Адаптивность для мобильных устройств обязательна: сайт должен корректно отображаться на всех экранах, а текст — легко читаться (шрифт не менее 16px).
Внутренняя перелинковка
Грамотная перелинковка удерживает пользователей на сайте. Ссылки на релевантные материалы помогают глубже погрузиться в тему. Добавляйте блоки «Читайте также» или «Похожие статьи».
Интерактивные элементы
Опросы, калькуляторы и тесты увеличивают время на сайте. Комментарии и обсуждения также работают на удержание аудитории. Четкие призывы к действию (CTA) направляют пользователя дальше по воронке.
Оптимизация сниппета и рост CTR: практическое руководство
Сниппет — первая точка контакта пользователя с вашим сайтом в поисковой выдаче. Его эффективность напрямую влияет на органический трафик.
| Элемент | Что оптимизировать | Инструмент проверки | KPI / Норма |
|---|---|---|---|
| Title | Длина 50–60 символов; ключ в начале; уникальная выгода или триггер (цифры, вопрос). | Google Search Console, «Яндекс Вебмастер» | CTR для топ-3: >20 %; топ-10: >5 % |
| Description | 120–160 символов; четкий ответ на запрос; призыв к действию (CTA). | GSC, Rich Results Test | Увеличение CTR на 10–25 % после оптимизации |
| Микроразметка | Schema: Article, FAQPage, HowTo, Product (рейтинг, цена). | Rich Results Test, Schema Validator | Расширенные сниппеты могут увеличить CTR на 20–40 % |
| URL | Короткий, читаемый; содержит ключевое слово. | Визуальная проверка в SERP | Понятный URL повышает доверие |
| Быстрые ссылки («Яндекс») | Логичная структура сайта, навигация, внутренние ссылки. | «Яндекс Вебмастер» | Дополнительные 5–10 % к общему CTR |
План A/B-тестирования сниппетов
- Выберите 5–10 страниц с хорошими позициями (топ-5), но низким CTR.
- Измените их Title и Description согласно рекомендациям выше.
- Отслеживайте динамику CTR в GSC или «Вебмастере» минимум 2–4 недели.
- Сравните результаты и масштабируйте успешные формулировки на другие страницы.
Улучшение поведенческих факторов — это комплексная работа. Чем лучше пользовательский опыт, тем выше позиции сайта. Регулярный аудит и тестирование помогут добиться стабильного роста трафика.
Чем опасна накрутка поведенческих факторов
Имитация поведения пользователей может дать кратковременный эффект, но алгоритмы «Яндекса» быстро распознают накрутку по аномалиям (резкие скачки трафика, одинаковые сценарии визитов) и пессимизируют сайт. Санкции могут привести к бану и полному исключению из выдачи.
Алгоритмы Google менее явно реагируют на накрутку, так как поведенческие метрики учитываются косвенно. Однако риск получить фильтр или ручную санкцию за неестественную активность остается. Подробнее об этом — в документации Google о спам-политиках.
В Kokoc.com мы используем только белые методы продвижения, что обеспечивает комплексное улучшение сайта и рост позиций без риска пессимизации. Например, при работе с сайтом медицинской клиники мы добились снижения процента отказов благодаря улучшению поведенческих факторов. Основные изменения:
- Полная переработка структуры сайта.
- Оптимизация расположения контента.
- Вывод на страницы прайс-листа.
- Добавление карты с адресами всех клиник.
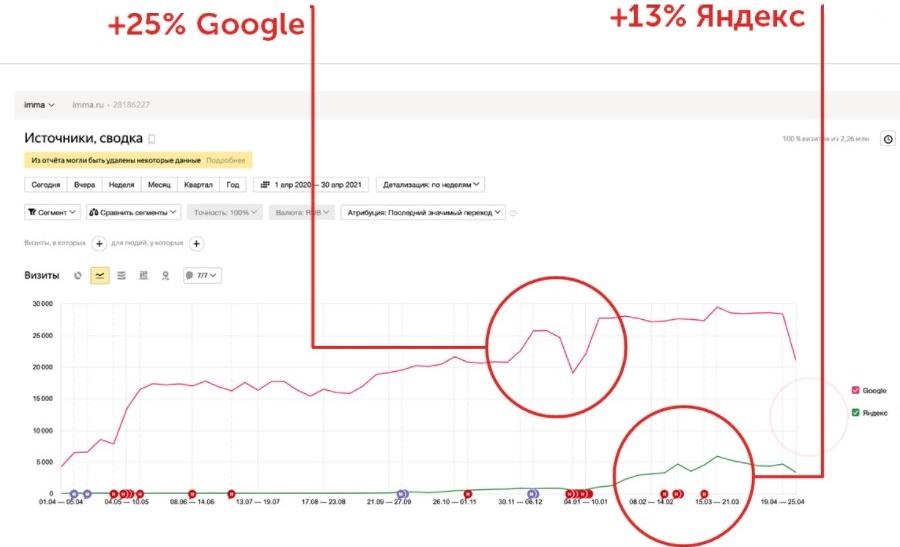
Кроме того, мы собрали объемную подборку способов улучшить поведенческие факторы на сайте и в поиске без накрутки, а также поможем выйти в топ Google и «Яндекса» с оплатой за результат.
Часто задаваемые вопросы (FAQ)
Можно ли быстро улучшить поведенческие факторы?
Нет, это постепенный процесс. Поведенческие сигналы анализируются на основе данных за длительный период. Быстрые изменения могут восприниматься как аномалия. Фокусируйтесь на комплексном улучшении: контент, UX, скорость. Первые результаты можно ожидать через 2–4 недели стабильной работы.
Как скорость сайта влияет на поведенческие факторы?
Напрямую. Медленная загрузка увеличивает отказы. Пользователи уходят, не дождавшись контента. Оптимизация скорости (LCP <2,5 с, INP <200 мс) снижает отказы и повышает вовлеченность. Используйте PageSpeed Insights для диагностики.
Различается ли влияние ПФ для мобильных и десктопных устройств?
Да. Поисковые системы учитывают тип устройства. Около 70 % трафика приходит с мобильных, и неадаптированные сайты теряют посетителей. Мобильная версия должна быть быстрой, удобной, с крупными кнопками и читаемым шрифтом (≥16px).
Нужно ли оптимизировать ПФ для каждой страницы отдельно?
Да, если у страниц разные цели. Главная, категории, карточки товаров, статьи блога — у каждого типа своя логика взаимодействия. Анализируйте метрики (отказы, время, глубину) отдельно для каждой группы страниц и оптимизируйте под их специфику.
Что важнее для SEO: внешние или внутренние поведенческие факторы?
Оба важны и работают в связке. Внешние (CTR) привлекают пользователя на сайт. Внутренние (вовлеченность, конверсии) удерживают его и подтверждают релевантность. Если CTR высокий, а UX плохой, пользователи вернутся в поиск, и позиции упадут.
Как часто нужно проверять и корректировать поведенческие факторы?
Базовый мониторинг (GA4, «Метрика», GSC) — минимум раз в месяц. Глубокий аудит — раз в квартал. При редизайне, изменениях в контенте или падении позиций — проверяйте ПФ немедленно. Настройте автоматические отчеты для отслеживания резких изменений метрик.
Коротко о главном
- ПФ — ключевой сигнал качества. CTR, время на сайте и глубина просмотра влияют на ранжирование, но характер влияния различается: косвенно в Google, более прямо в «Яндексе».
- «Яндекс» глубже анализирует поведение («Вебвизор», возвраты в поиск), Google делает фокус на Page Experience (скорость, мобильность, Core Web Vitals).
- Оптимизация ПФ ведет к росту трафика. Работайте над сниппетами, контентом, скоростью загрузки и перелинковкой.
- Накрутка — это риск. Искусственные ПФ обнаруживаются (особенно «Яндексом») и ведут к санкциям. Используйте только белые методы.
- Аналитика — основа успеха. GA4 (Engagement Rate), «Яндекс Метрика» («Вебвизор»), GSC и «Вебмастер» — необходимый набор для анализа и улучшения ПФ.
- SEO будущего — для людей. Только полезные и удобные сайты остаются в топе. ПФ — это инструмент очистки выдачи от некачественных ресурсов.




.png)

.png)
.png)

Комментарии (12)
Оставить комментарий